Déploiement de PySpark Microservice sur Kubernetes : révolutionner les lacs de données avec Ilum.

Salutations aux passionnés d’Ilum et aux fans de Python ! Nous sommes ravis de dévoiler une nouvelle fonctionnalité très attendue qui devrait vous aider dans votre parcours de science des données : la prise en charge complète de Python dans Ilum. Pour ceux qui travaillent dans le monde des données, Python et Apache Spark forment depuis longtemps un duo emblématique, gérant de manière transparente de vastes volumes de données et des calculs complexes. Et maintenant, avec la dernière mise à niveau d’Ilum, vous pouvez exploiter la puissance de Python directement dans votre environnement de lac de données préféré.
Cet article de blog est votre visite guidée pour explorer cette fonctionnalité. Nous allons commencer par une simple tâche Apache Spark écrite en Python, l’exécuter sur Ilum, puis aller plus loin. Nous allons transformer le code initial pour prendre en charge un mode interactif, vous offrant un accès direct à la tâche Spark via l’API d’Ilum. À la fin de ce parcours, vous disposerez d’un microservice basé sur Python répondant aux appels d’API, le tout fonctionnant sans problème sur Ilum.
Alors, êtes-vous prêt à améliorer votre jeu de données avec Python et Ilum ? Commençons.
Tous les exemples sont disponibles sur notre Référentiel GitHub .
Étape 1 : Écriture d’une tâche Apache Spark simple en Python.
Avant de nous lancer dans l’aventure Python avec Ilum, nous devons nous assurer que notre environnement est bien équipé. Pour exécuter une tâche Spark, vous devez avoir installé Ilum et PySpark. Vous pouvez utiliser pip, l’installateur du package Python, pour configurer PySpark. Assurez-vous d’utiliser Python >=3.9.
pip install pyspark Pour la configuration et l’accès à Ilum, veuillez suivre les instructions fournies ici .
1.1 Exemple SparkPi.
Plongeons maintenant dans l’écriture de notre travail Spark. Nous allons commencer par un exemple simple de SparkPi
Importer sys
à partir de random import random
à partir de l’opérateur import ajouter
à partir de pyspark.sql import SparkSession
si __name__ == « __main__ » :
spark = SparkSession \
.constructeur\
.appName(« PythonPi ») \
.getOrCreate()
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions
def f(_ : int) -> float :
x = random() * 2 - 1
y = random() * 2 - 1
Retourner 1 si x ** 2 + y ** 2 <= 1 sinon 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print(« Pi est à peu près %f » % (4,0 * compte / n))
spark.stop() Enregistrez ce script sous le nom ilum_python_simple.py
Une fois notre job Spark prêt, il est temps de l’exécuter sur Ilum. Ilum offre la possibilité de soumettre des tâches à l’aide de l’interface utilisateur Ilum ou de l’API REST.
Commençons par l’interface utilisateur avec le Fonction de travail unique.
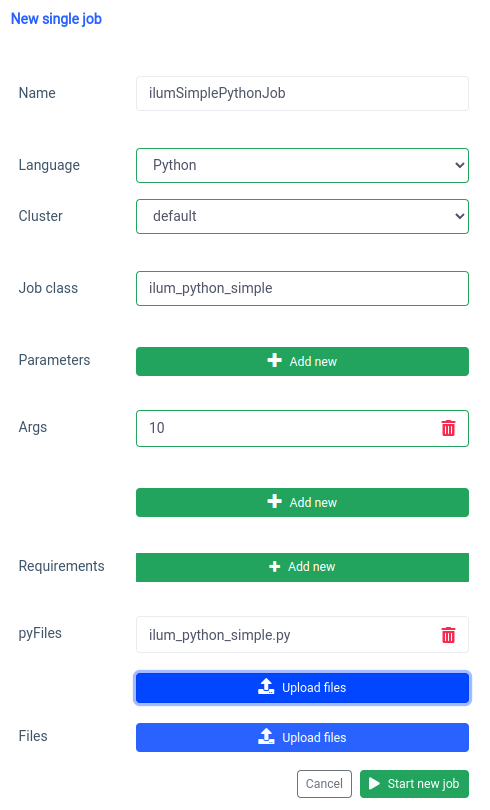
Nous pouvons réaliser la même chose avec le API , mais d’abord, nous devons exposer l’API ilum-core avec port forward.
kubectl port-forward svc/ilum-core 9888:9888 Avec le port exposé, nous pouvons faire un appel API.
curl -X POST 'localhost :9888/api/v1/job/submit' \
--form 'name="ilumSimplePythonJob"' \
--form 'clusterName="default"' \
--form 'jobClass="ilum_python_simple"' \
--form 'args="10"' \
--form 'pyFiles=@"/chemin/vers/ilum_python_simple.py"' \
--form 'language="PYTHON"' Appel API
En conséquence, nous recevrons l’id de la tâche créée.
{"jobId » :"20230724-1154-m78f3gmlo5j"} Résultat
Pour vérifier les logs du job, nous pouvons faire un appel API à
curl localhost :9888/api/v1/job/20230724-1154-m78f3gmlo5j/logs Appel API
Et c’est tout ! Vous avez écrit et exécuté une tâche Python Spark simple sur Ilum. Regardons un exemple un peu plus avancé qui nécessite des bibliothèques Python supplémentaires.
1.2 Exemple de job avec numpy.
Dans cette section, nous allons passer en revue un exemple pratique d’une tâche Spark écrite en Python. Ce travail implique la lecture d’un ensemble de données, son traitement, l’entraînement d’un modèle d’apprentissage automatique sur celui-ci et l’enregistrement des prédictions. Nous allons utiliser un Tel-churn.csv fichier, que vous pouvez trouver dans notre Référentiel GitHub . Pour faciliter les choses, nous avons téléchargé ce fichier dans un compartiment nommé ilum-files dans l’instance intégrée de MinIO, qui est automatiquement accessible à partir de l’instance Ilum. Cela signifie que vous n’aurez pas à vous soucier de la configuration des accès pour cet exemple - Ilum s’en charge. Toutefois, si vous souhaitez récupérer des données à partir d’un autre compartiment ou utiliser Amazon S3 dans vos propres projets, vous devrez configurer les accès en conséquence.
Maintenant que nos données sont prêtes, commençons à écrire notre job Spark en Python. Voici l’exemple de code complet :
à partir de pyspark.sql import SparkSession
à partir de pyspark.ml pipeline d’importation
from pyspark.ml.feature import StringIndexer, VectorAssembler
à partir de pyspark.ml.classification import LogisticRegression
si __name__ == « __main__ » :
spark = SparkSession \
.constructeur\
.appName(« IlumAdvancedPythonExample ») \
.getOrCreate()
df = spark.read.csv('s3a ://ilum-files/Tel-churn.csv', header=True, inferSchema=True)
categoricalColumns = ['genre', 'Partenaire', 'Personnes à charge', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV',
'StreamingMovies', 'Contrat', 'PaperlessBilling', 'PaymentMethod']
étapes = []
pour categoricalCol dans categoricalColumns :
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + « Index »)
stages += [stringIndexer]
label_stringIdx = StringIndexer(inputCol="Désabonnement », outputCol="étiquette »)
étapes += [label_stringIdx]
numericCols = ['SeniorCitizen', 'tenure', 'MonthlyCharges']
assemblerInputs = [c + « Index » pour c dans categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="fonctionnalités »)
étapes += [assembleur]
pipeline = Pipeline(stages=stages)
pipelineModel = pipeline.fit(df)
df = pipelineModel.transform(df)
train, test = df.randomSplit([0.7, 0.3], seed=42)
lr = LogisticRegression(featuresCol="features », labelCol="label », maxIter=10)
lrModel = lr.fit(train)
predictions = lrModel.transform(test)
predictions.select(« customerID », « label », « prediction »).show(5)
predictions.select(« customerID », « label », « prediction »).write.option(« en-tête », « true ») \
.csv('s3a ://ilum-files/predictions')
spark.stop() Plongeons dans le code :
à partir de pyspark.sql import SparkSession
à partir de pyspark.ml pipeline d’importation
from pyspark.ml.feature import StringIndexer, VectorAssembler
à partir de pyspark.ml.classification import LogisticRegression Ici, nous importons les modules PySpark nécessaires pour créer une session Spark, créer un pipeline d’apprentissage automatique, prétraiter les données et exécuter un modèle de régression logistique.
spark = SparkSession \
.constructeur\
.appName(« IlumAdvancedPythonExample ») \
.getOrCreate() Nous initialisons un SparkSession , qui est le point d’entrée de n’importe quelle fonctionnalité dans Spark. C’est ici que nous définissons le nom de l’application qui apparaîtra sur l’interface utilisateur web de Spark.
df = spark.read.csv('s3a ://ilum-files/Tel-churn.csv', header=True, inferSchema=True) Nous lisons un fichier CSV stocké sur un bucket minio. Le header=Vrai indique à Spark d’utiliser la première ligne du fichier CSV comme en-tête, tandis que inferSchema=Vrai permet à Spark de déterminer automatiquement le type de données de chaque colonne.
categoricalColumns = ['genre', 'Partenaire', 'Personnes à charge', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV',
'StreamingMovies', 'Contrat', 'PaperlessBilling', 'PaymentMethod'] Nous spécifions les colonnes de nos données qui sont catégorielles. Ceux-ci seront transformés ultérieurement à l’aide d’un StringIndexer.
étapes = []
pour categoricalCol dans categoricalColumns :
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + « Index »)
stages += [stringIndexer] Ici, nous allons parcourir notre liste de colonnes catégorielles et créer un StringIndexer pour chacune. Les StringIndexers encodent des colonnes de chaînes catégorielles en une colonne d’index. La colonne d’index transformée sera nommée comme le nom de la colonne d’origine ajouté à « Index ».
numericCols = ['SeniorCitizen', 'tenure', 'MonthlyCharges']
assemblerInputs = [c + « Index » pour c dans categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="fonctionnalités »)
étapes += [assembleur] Ici, nous préparons les données pour notre modèle d’apprentissage automatique. Nous créons un VectorAssembler qui prendra toutes nos colonnes de fonctionnalités (à la fois catégorielles et numériques) et les assemblera en une seule colonne vectorielle. Il s’agit d’une exigence pour la plupart des algorithmes d’apprentissage automatique dans Spark.
train, test = df.randomSplit([0.7, 0.3], seed=42) Nous divisons nos données en un ensemble d’entraînement et un ensemble de test, avec 70 % des données pour l’entraînement et les 30 % restants pour les tests.
lr = LogisticRegression(featuresCol="features », labelCol="label », maxIter=10)
lrModel = lr.fit(train) Nous entraînons un modèle de régression logistique sur nos données d’entraînement.
predictions = lrModel.transform(test)
predictions.select(« customerID », « label », « prediction »).show(5)
predictions.select(« customerID », « label », « prediction »).write.option(« en-tête », « true ») \
.csv('s3a ://ilum-files/predictions') Enfin, nous utilisons notre modèle entraîné pour faire des prédictions sur notre ensemble de test, en affichant les 5 premières prédictions. Ensuite, nous réécrivons ces prédictions dans notre compartiment minio.
Enregistrez ce script sous le nom ilum_python_advanced.py
pyspark.ml utilise numpy comme dépendance qui n’est pas installée par défaut, nous devons donc le spécifier comme une exigence.
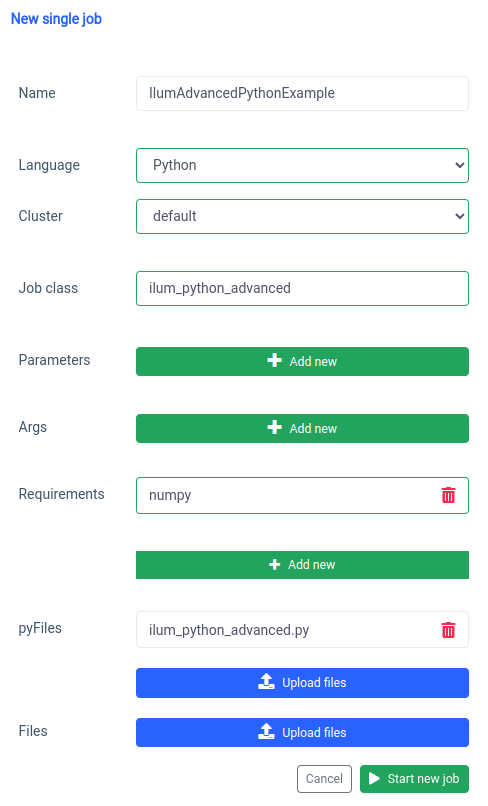
Et la même chose peut être faite via l’API.
curl -X POST 'localhost :9888/api/v1/job/submit' \
--form 'name="IlumAdvancedPythonExample"' \
--form 'clusterName="default"' \
--form 'jobClass="ilum_python_advanced"' \
--form 'pyRequirements="numpy"' \
--form 'pyFiles=@"/chemin/vers/ilum_python_advanced.py"' \
--form 'language="PYTHON"' Appel API
Dans les sections suivantes, nous allons transformer les deux scripts Python en un interactif Spark en tirant pleinement parti des capacités d’Ilum.
Étape 2 : Transition vers le mode interactif
Le mode interactif est une fonctionnalité intéressante qui rend le développement Spark plus dynamique, en vous donnant la possibilité d’exécuter, d’interagir et de contrôler vos tâches Spark en temps réel. Il est conçu pour ceux qui recherchent un contrôle plus direct sur leurs applications Spark.
Considérez le mode interactif comme une conversation directe avec votre travail Spark. Vous pouvez introduire des données, demander des transformations et récupérer des résultats, le tout en temps réel. Cela améliore considérablement l’agilité et la capacité de votre pipeline de traitement des données, ce qui le rend plus adaptable et réactif à l’évolution des besoins.
Maintenant que nous sommes familiarisés avec la création d’une tâche Spark de base en Python, allons plus loin en transformant notre tâche en une tâche interactive qui peut tirer parti des capacités en temps réel d’Ilum.
2.1 Exemple SparkPi.
Pour illustrer comment passer notre travail en mode interactif, nous allons ajuster notre ilum_python_simple.py script.
à partir de random import random
à partir de l’opérateur import ajouter
depuis ilum.api import IlumJob
classe SparkPiInteractiveExample(IlumJob) :
def run(self, spark, config) :
partitions = int(config.get('partitions', '5'))
n = 100000 * partitions
def f(_ : int) -> float :
x = random() * 2 - 1
y = random() * 2 - 1
Retourner 1 si x ** 2 + y ** 2 <= 1 sinon 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
return « Pi est à peu près %f » % (4,0 * compte / n) Enregistrez ceci sous ilum_python_simple_interactive.py
Il n’y a que quelques différences par rapport au SparkPi original.
1. Paquet Ilum
Pour commencer, nous importons le IlumJob à partir du package ilum, qui sert de classe de base pour notre travail interactif.
La logique du travail Spark est encapsulée dans une classe qui s’étend IlumJob , en particulier dans le cadre de son Courir méthode. Nous pouvons ajouter le package ilum avec :
pip install ilum 2. Tâche Spark dans une classe
La logique du travail Spark est encapsulée dans une classe qui s’étend IlumJob , en particulier dans le cadre de son Courir méthode.
classe SparkPiInteractiveExample(IlumJob) :
def run(self, spark, config) :
# Logique du poste ici L’encapsulation de la logique de travail dans une classe est essentielle pour que l’infrastructure Ilum puisse gérer le travail et ses ressources. Cela rend également le travail sans état et réutilisable.
3. Les paramètres sont gérés différemment :
Nous prenons tous les arguments du dictionnaire de configuration
partitions = int(config.get('partitions', '5')) Ce décalage permet un passage plus dynamique des paramètres et s’intègre à la gestion de la configuration d’Ilum.
4. Le résultat est renvoyé au lieu d’être imprimé :
Le résultat est renvoyé par la commande Courir méthode.
return « Pi est à peu près %f » % (4,0 * compte / n) En renvoyant le résultat, Ilum peut le gérer de manière plus flexible. Par exemple, Ilum pourrait sérialiser le résultat et le rendre accessible via un appel API.
5. Pas besoin de gérer manuellement la session Spark
Ilum gère la session Spark pour nous. Il est automatiquement injecté dans le Courir et nous n’avons pas besoin de l’arrêter manuellement.
def run(self, spark, config) : Ces modifications mettent en évidence la transition d’un travail Spark autonome à un travail Ilum interactif. L’objectif est d’améliorer la flexibilité et la réutilisabilité du travail, en le rendant plus adapté aux calculs dynamiques, interactifs et à la volée.
L’ajout d’une tâche d’étincelle interactive est géré par la fonction « nouveau groupe ».
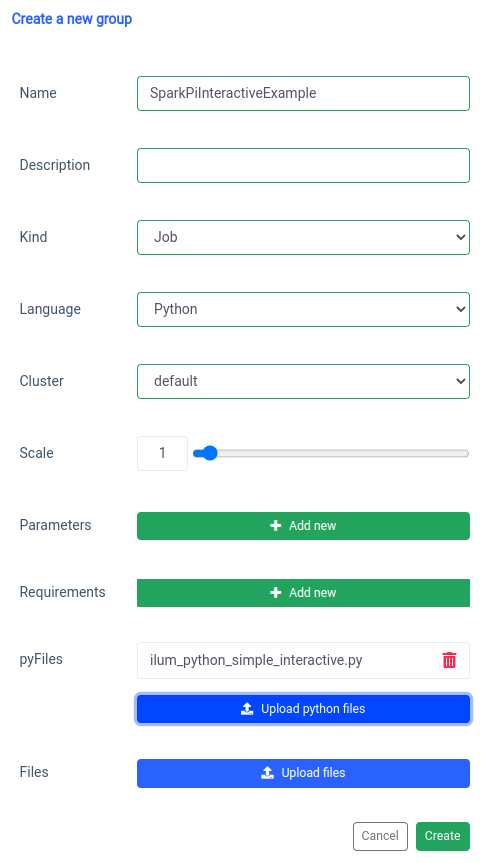
Et l’exécution avec la fonction de travail interactive sur l’interface utilisateur.
Le nom de la classe doit être spécifié sous la forme d’un pythonFileName.PythonClassImplementingIlumJob
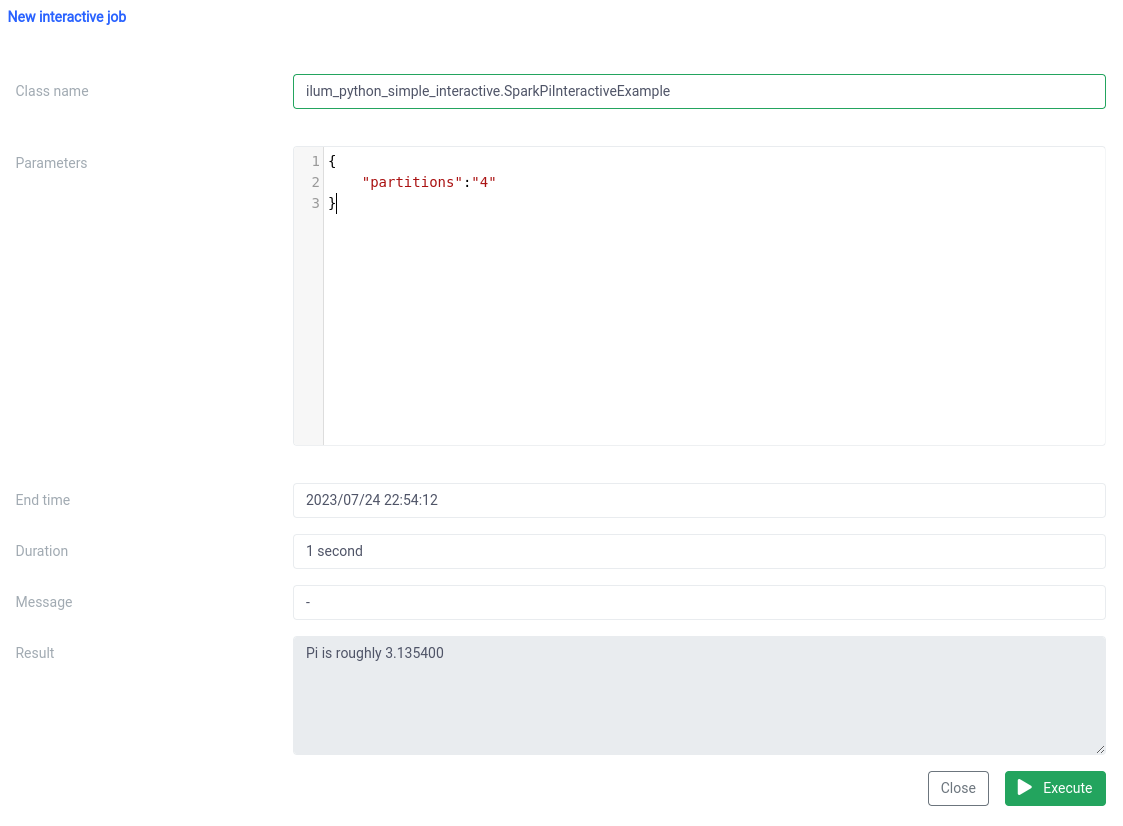
Nous pouvons réaliser la même chose avec le API .
1. Création d’un groupe
curl -X POST 'localhost :9888/api/v1/group' \
--form 'name="SparkPiInteractiveExample"' \
--form 'kind="JOB"' \
--form 'clusterName="default"' \
--form 'pyFiles=@"/chemin/vers/ilum_python_simple_interactive.py"' \
--form 'language="PYTHON"' Appel API
{"groupId » :"20230726-1638-mjrw3"} Résultat
2. Exécution des tâches
curl -X POST 'localhost :9888/api/v1/group/20230726-1638-mjrw3/job/execute' \
-H 'Type-de-contenu : application/json' \
-d '{ « jobClass » :"ilum_python_simple_interactive. SparkPiInteractiveExample », « jobConfig » : {"partitions » :"10"}, « type » :"interactive_job_execute"}' Appel API
{
« jobInstanceId » :"20230726-1638-mjrw3-a1srahhu »,
« jobId » :"20230726-1638-mjrw3-wwt5a »,
« groupId » :"20230726-1638-mjrw3 »,
« startTime » :1690390323154,
« endTime » :1690390325200,
« jobClass » :"ilum_python_simple_interactive. SparkPiInteractiveExample",
« jobConfig » :{
« partitions » :"10 »
},
« result » :"Pi est à peu près de 3,149400 »,
« error » :null
} Résultat
2.2 Exemple de job avec numpy.
Regardons notre deuxième exemple.
à partir de pyspark.sql import SparkSession
à partir de pyspark.ml pipeline d’importation
from pyspark.ml.feature import StringIndexer, VectorAssembler
à partir de pyspark.ml.classification import LogisticRegression
depuis ilum.api import IlumJob
classe LogisticRegressionJobExample(IlumJob) :
def run(self, spark_session : SparkSession, config : dict) -> str :
df = spark_session.read.csv(config.get('inputFilePath', 's3a ://ilum-files/Tel-churn.csv'), header=True,
inferSchema=Vrai)
categoricalColumns = ['genre', 'Partenaire', 'Personnes à charge', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV',
'StreamingMovies', 'Contrat', 'PaperlessBilling', 'PaymentMethod']
étapes = []
pour categoricalCol dans categoricalColumns :
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + « Index »)
stages += [stringIndexer]
label_stringIdx = StringIndexer(inputCol="Désabonnement », outputCol="étiquette »)
étapes += [label_stringIdx]
numericCols = ['SeniorCitizen', 'tenure', 'MonthlyCharges']
assemblerInputs = [c + « Index » pour c dans categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="fonctionnalités »)
étapes += [assembleur]
pipeline = Pipeline(stages=stages)
pipelineModel = pipeline.fit(df)
df = pipelineModel.transform(df)
train, test = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))],
seed=int(config.get('seed', '42')))
lr = LogisticRegression(featuresCol="features », labelCol="label », maxIter=int(config.get('maxIter', '5')))
lrModel = lr.fit(train)
predictions = lrModel.transform(test)
return '{}'.format(predictions.select(« customerID », « label », « prediction »).limit(
int(config.get('rowLimit', '5'))).toJSON().collect()) 1. Nous encapsulons le travail dans une classe, comme dans l’exemple précédent :
classe LogisticRegressionJobExample(IlumJob) :
def run(self, spark_session : SparkSession, config : dict) -> str :
# Logique du poste ici Encore une fois, la logique de la tâche est encapsulée dans le fichier Courir Procédé d’extension d’une classe IlumJob , aidant Ilum à gérer le travail efficacement.
2. Tous les paramètres, y compris ceux du pipeline de données (comme les chemins d’accès aux fichiers et les hyperparamètres de régression logistique), sont obtenus à partir de la commande Configuration dictionnaire:
df = spark_session.read.csv(config.get('inputFilePath', 's3a ://ilum-files/Tel-churn.csv'), header=True, inferSchema=True)
train, test = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))], seed=int(config.get('seed', '42')))
lr = LogisticRegression(featuresCol="features », labelCol="label », maxIter=int(config.get('maxIter', '5'))) En centralisant tous les paramètres en un seul endroit, Ilum fournit une méthode uniforme et cohérente de configuration et de réglage du travail.
Le résultat de la tâche, plutôt que d’être écrit à un emplacement spécifique, est renvoyé sous la forme d’une chaîne JSON :
return '{}'.format(predictions.select(« customerID », « label », « prediction »).limit(int(config.get('rowLimit', '5'))).toJSON().collect()) Cela permet une gestion plus dynamique et plus flexible du résultat de la tâche, qui peut ensuite être traité ultérieurement ou exposé via une API, en fonction des besoins de l’application.
Ce code montre parfaitement comment nous pouvons intégrer de manière transparente les tâches PySpark à Ilum pour permettre des pipelines de traitement de données interactifs et pilotés par API. Qu’il s’agisse d’exemples simples comme l’approximation de Pi ou de cas plus complexes comme la régression logistique, les tâches interactives d’Ilum sont polyvalentes, adaptables et efficaces.
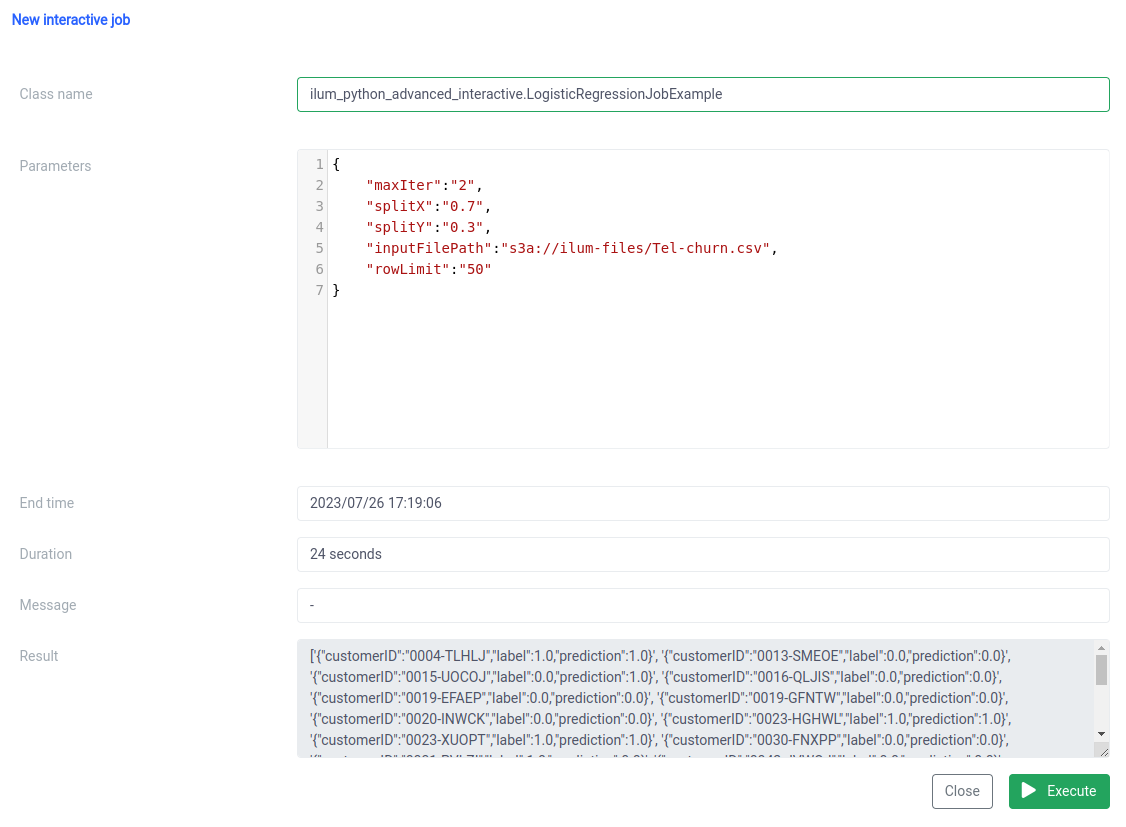
Étape 3 : Transformer votre tâche Spark en microservice
Les microservices apportent un changement de paradigme par rapport à la structure d’application monolithique traditionnelle à une approche plus modulaire et agile. En décomposant une application complexe en petits services faiblement couplés, il devient plus facile de créer, de maintenir et de faire évoluer chaque service indépendamment en fonction d’exigences spécifiques. Lorsqu’il est appliqué à notre travail Spark, cela signifie que nous avons pu créer un service de traitement de données robuste qui pourrait être mis à l’échelle, géré et mis à jour sans affecter les autres parties de notre pile d’applications.
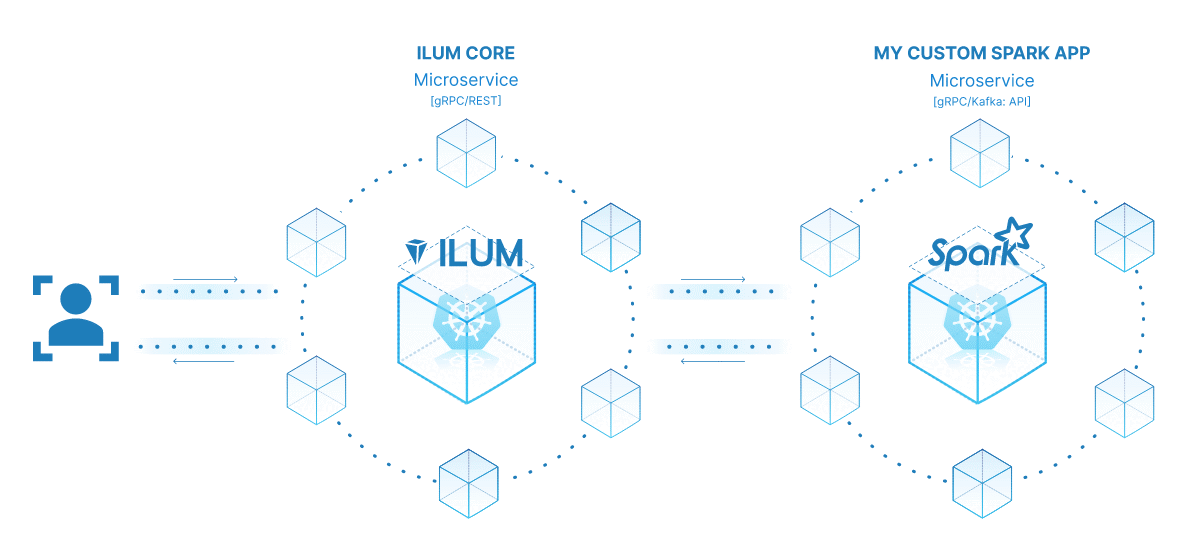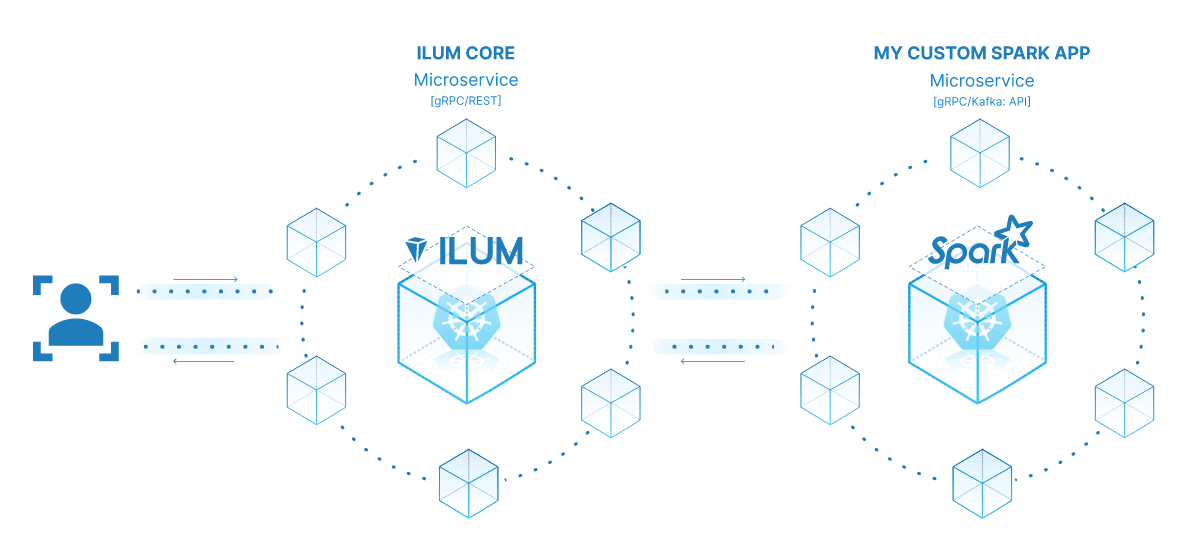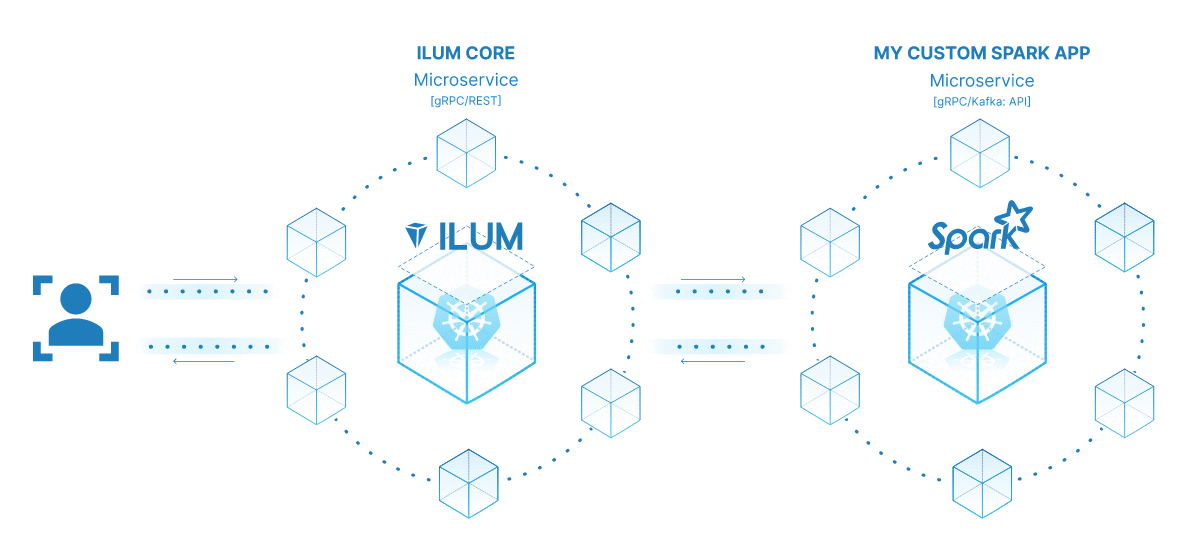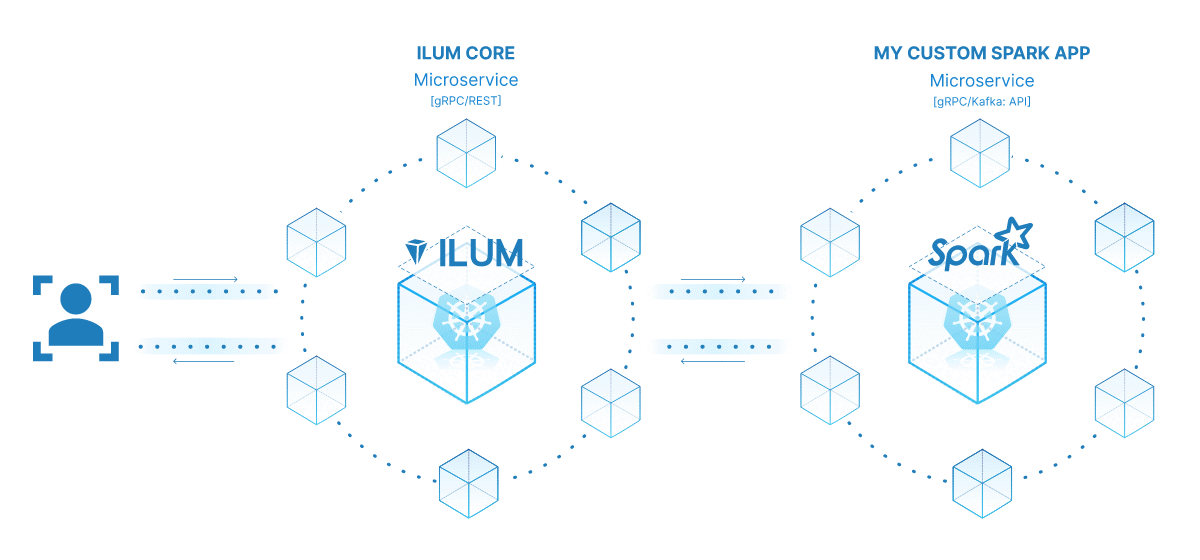
La puissance de la transformation de votre tâche Spark en microservice réside dans sa polyvalence, son évolutivité et ses capacités d’interaction en temps réel. Un microservice est un composant déployable indépendamment d’une application qui s’exécute en tant que processus distinct. Il communique avec d’autres composants via des API bien définies, ce qui vous donne la liberté de concevoir, de développer, de déployer et de faire évoluer chaque microservice indépendamment.
Dans le contexte d’Ilum, une tâche Spark interactive peut être traitée comme un microservice. La méthode « run » de la tâche agit comme un point de terminaison d’API. Chaque fois que vous appelez cette méthode via l’API d’Ilum, vous effectuez une requête à ce microservice. Cela ouvre la possibilité d’interactions en temps réel avec votre tâche Spark.
Vous pouvez envoyer des requêtes à votre microservice à partir de diverses applications ou scripts, en récupérant des données et en traitant les résultats à la volée. De plus, cela ouvre la possibilité de construire des architectures plus complexes, orientées services, autour de vos pipelines de traitement de données.
L’un des principaux avantages de cette configuration est l’évolutivité. Grâce à l’interface utilisateur ou à l’API Ilum, vous pouvez augmenter ou réduire la taille de votre travail (microservice) en fonction de la charge ou de la complexité du calcul. Vous n’avez pas à vous soucier de la gestion manuelle des ressources ou de l’équilibrage de charge. L’équilibreur de charge interne d’Ilum distribuera les appels d’API entre les instances de votre tâche Spark, garantissant ainsi une utilisation efficace des ressources.
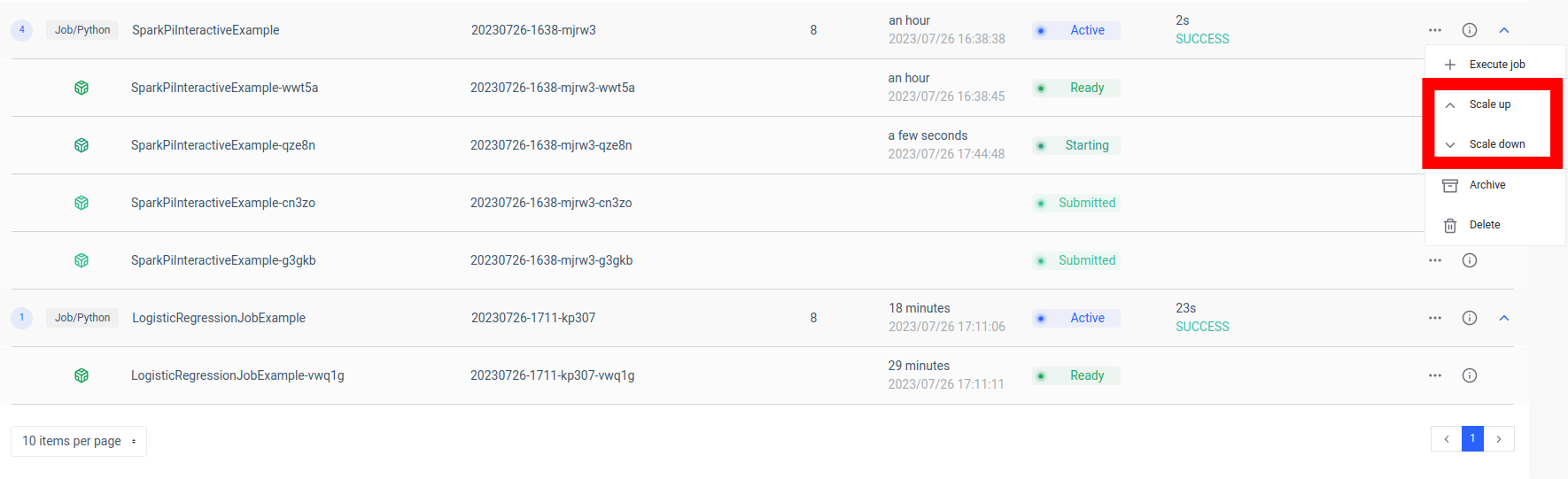
Gardez à l’esprit que le temps de traitement réel de la tâche dépend de la complexité de la tâche Spark et des ressources qui lui sont allouées. Cependant, grâce à l’évolutivité fournie par Kubernetes, vous pouvez facilement faire évoluer vos ressources à mesure que les exigences de votre travail augmentent.
Cette combinaison d’Ilum, d’Apache Spark et de microservices offre une nouvelle façon agile de traiter vos données, de manière efficace, évolutive et réactive !

L’architecture des microservices de données change la donne
Nous avons parcouru un long chemin depuis que nous avons commencé à transformer une simple tâche Apache Spark Python en un microservice à part entière à l’aide d’Ilum. Nous avons vu à quel point il était facile d’écrire une tâche Spark, de l’adapter pour qu’elle fonctionne en mode interactif et finalement de l’exposer en tant que microservice à l’aide de l’API robuste d’Ilum. En cours de route, nous avons tiré parti de la puissance de Python, des capacités d’Apache Spark, ainsi que de la flexibilité et de l’évolutivité d’Ilum. Cette combinaison a non seulement transformé nos capacités de traitement des données, mais a également changé notre façon de penser l’architecture des données.
Le voyage ne s’arrête pas là. Avec la prise en charge complète de Python sur Ilum, un nouveau monde de possibilités s’ouvre pour le traitement et l’analyse des données. Alors que nous continuons à développer et à améliorer Ilum, nous sommes enthousiasmés par les possibilités futures que Python apporte à notre plateforme. Nous pensons qu’avec Python et Ilum ensemble, nous n’en sommes qu’au début de la redéfinition de ce qui est possible dans le monde de l’architecture des microservices de données.
Rejoignez-nous dans cette aventure passionnante, et façonnons ensemble l’avenir du traitement des données !