Comment optimiser votre cluster Spark avec des travaux Spark interactifs

Dans cet article, vous apprendrez :
- Comment réduire le temps d’exécution de votre travail Spark
- Qu’est-ce qu’un job interactif chez Ilum
- Comment exécuter une tâche d’étincelle interactive
- Différences entre l’exécution d’une tâche Spark à l’aide de l’API Ilum et de l’API Spark
Types de tâches Ilum
Il existe trois types de tâches que vous pouvez exécuter dans Ilum : Emploi unique , Emploi interactif et Code interactif . Dans cet article, nous allons nous concentrer sur les Emploi interactif type. Cependant, il est important de connaître les différences entre les trois types d’emplois, alors faisons un rapide tour d’horizon de chacun d’eux.
Avec emplois uniques , vous pouvez soumettre des programmes de type code. Ils vous permettent de soumettre une application Spark au cluster, avec du code précompilé, sans interaction pendant l’exécution. Dans ce mode, vous devez envoyer un jar compilé à Ilum, qui est utilisé pour lancer une seule tâche. Vous pouvez soit l’envoyer directement, soit utiliser les informations d’identification AWS pour l’obtenir à partir d’un compartiment S3. Un exemple typique d’utilisation d’une seule tâche serait une sorte de tâche de préparation des données.
Ilum fournit également un interactif Mode de code , qui vous permet d’envoyer des commandes au moment de l’exécution. Cela est utile pour les tâches où vous devez interagir avec les données, telles que l’analyse exploratoire des données.
Emploi interactif
Les travaux interactifs ont des sessions de longue durée, qui vous permettent d’envoyer des données d’instance de travail à exécuter immédiatement. La caractéristique principale d’un tel mode est que vous n’avez pas à attendre que le contexte Spark soit initialisé. Si les utilisateurs pointaient vers le même ID de tâche, ils interagissaient avec le même contexte Spark. Ilum encapsule la logique de l’application Spark dans une tâche Spark de longue durée capable de gérer immédiatement les demandes de calcul, sans qu’il soit nécessaire d’attendre l’initialisation du contexte Spark.
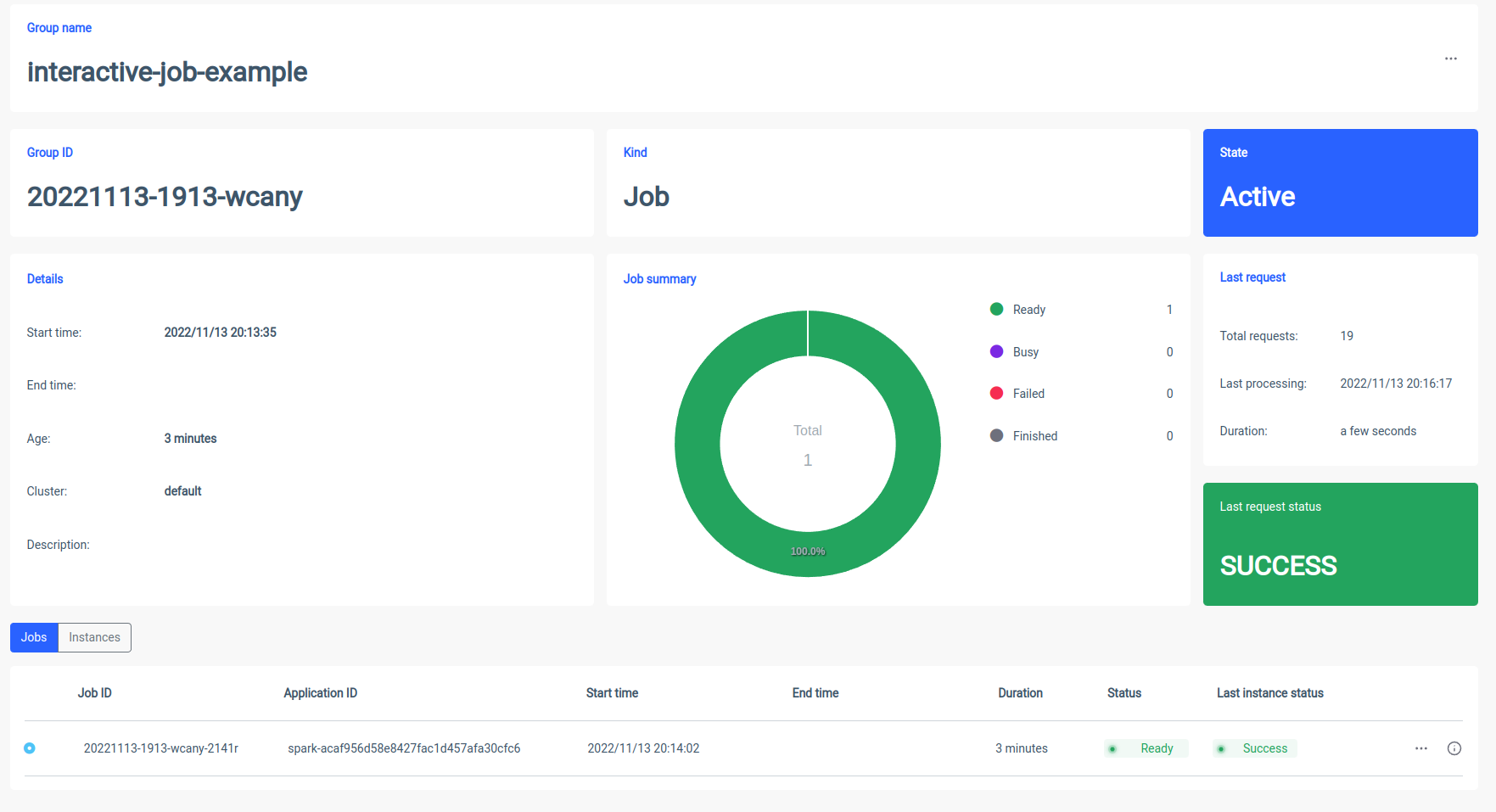
Démarrage d’une tâche interactive
Voyons comment la session interactive d’Ilum peut être lancée. La première chose que nous devons faire est de mettre en place Ilum. Vous pouvez le faire facilement avec le minikube. Un tutoriel d’installation d’Ilum est disponible sous ce lien . Dans l’étape suivante, nous devons créer un fichier jar qui contient une implémentation de l’interface de travail d’Ilum. Pour utiliser l’API de travail Ilum, nous devons l’ajouter au projet avec certains gestionnaires de dépendances, tels que Maven ou Gradle. Dans cet exemple, nous allons utiliser du code Scala avec un Gradle pour calculer PI.
L’exemple complet est disponible sur notre Lien avec GitHub .
Si vous préférez ne pas le construire vous-même, vous pouvez trouver le fichier jar compilé ici .
La première étape consiste à créer un dossier pour notre projet et à y changer le répertoire.
$ mkdir exemple-de-job-interactif
$ cd exemple-de-job-interactif Si vous n’avez pas la dernière version de Gradle installée sur votre ordinateur, vous pouvez vérifier comment procéder ici . Exécutez ensuite la commande suivante dans un terminal à partir du répertoire du projet :
$ gradle init Choisissez une application Scala avec Groovy comme DSL. Le résultat doit ressembler à ceci :
Démarrage d’un démon Gradle (les versions suivantes seront plus rapides)
Sélectionnez le type de projet à générer :
1 : de base
2 : Candidature
3 : Bibliothèque
4 : Plug-in Gradle
Entrez la sélection (par défaut : de base) [1..4] 2
Sélectionnez la langue de mise en œuvre :
1 : C++
2 : Groovy
3 : Java
4 : Kotlin
5 : Scala
6 : Martinet
Entrez la sélection (par défaut : Java) [1..6] 5
Diviser les fonctionnalités en plusieurs sous-projets ?
1 : Non - un seul projet d’application
2 : Oui - Projets d’application et de bibliothèque
Entrez la sélection (par défaut : non - un seul projet d’application) [1..2] 1
Sélectionnez le script de construction DSL :
1 : Groovy
2 : Kotlin
Entrez la sélection (par défaut : Groovy) [1..2] 1
Générer une build à l’aide de nouvelles API et de nouveaux comportements (certaines fonctionnalités peuvent changer dans la prochaine version mineure) ? (par défaut : non) [oui, non] non
Nom du projet (par défaut : interactive-job-example) :
Package source (par défaut : interactive.job.example) :
> Tâche :init
Obtenez plus d’aide pour votre projet : https://docs.gradle.org/7.5.1/samples/sample_building_scala_applications_multi_project.html
CONSTRUIRE AVEC SUCCÈS en 30 secondes
2 tâches exploitables : 2 exécutées Maintenant, nous devons ajouter le dépôt Ilum et les dépendances nécessaires dans votre build.gradle lime. Dans ce tutoriel, nous allons utiliser Scala 2.12.
dépendances {
implémentation 'org.scala-lang :scala-library :2.12.16'
implémentation 'cloud.ilum :ilum-job-api :5.0.1'
compileOnly 'org.apache.spark :spark-sql_2.12:3.1.2'
} Maintenant, nous pouvons créer une classe Scala qui étend le Job d’Ilum et qui calcule PI :
package interactive.job.example
import cloud.ilum.job.Job
import org.apache.spark.sql.SparkSession
importer scala.math.random
class InteractiveJobExample extends Job {
override def run(sparkSession : SparkSession, config : Map[String, Any]) : Option[String] = {
val tranches = config.getOrElse(« tranches », « 2 »).toString.toInt
val n = math.min(100000L * tranches, Int.MaxValue).toInt
val count = sparkSession.sparkContext.parallelize(1 jusqu’à n, tranches).map { i =>
val x = aléatoire * 2 - 1
val y = aléatoire * 2 - 1
si (x * x + y * y <= 1) 1 sinon 0
}.réduire(_ + _)
Some(s"Pi est à peu près ${4.0 * count / (n - 1)} »)
}
} Si Gradle a généré des classes principales ou de test, il vous suffit de les supprimer du projet et d’en créer une version.
$ gradle build Le fichier jar généré doit être dans ' ./exemple-de-travail-interactif/app/build/libs/app.jar ', nous pouvons ensuite revenir à Ilum. Une fois que tous les pods sont en cours d’exécution, veuillez créer une redirection de port pour ilum-ui :
kubectl port-forward svc/ilum-ui 9777:9777 Ouvrez Ilum UI dans votre navigateur et créez un nouveau groupe :
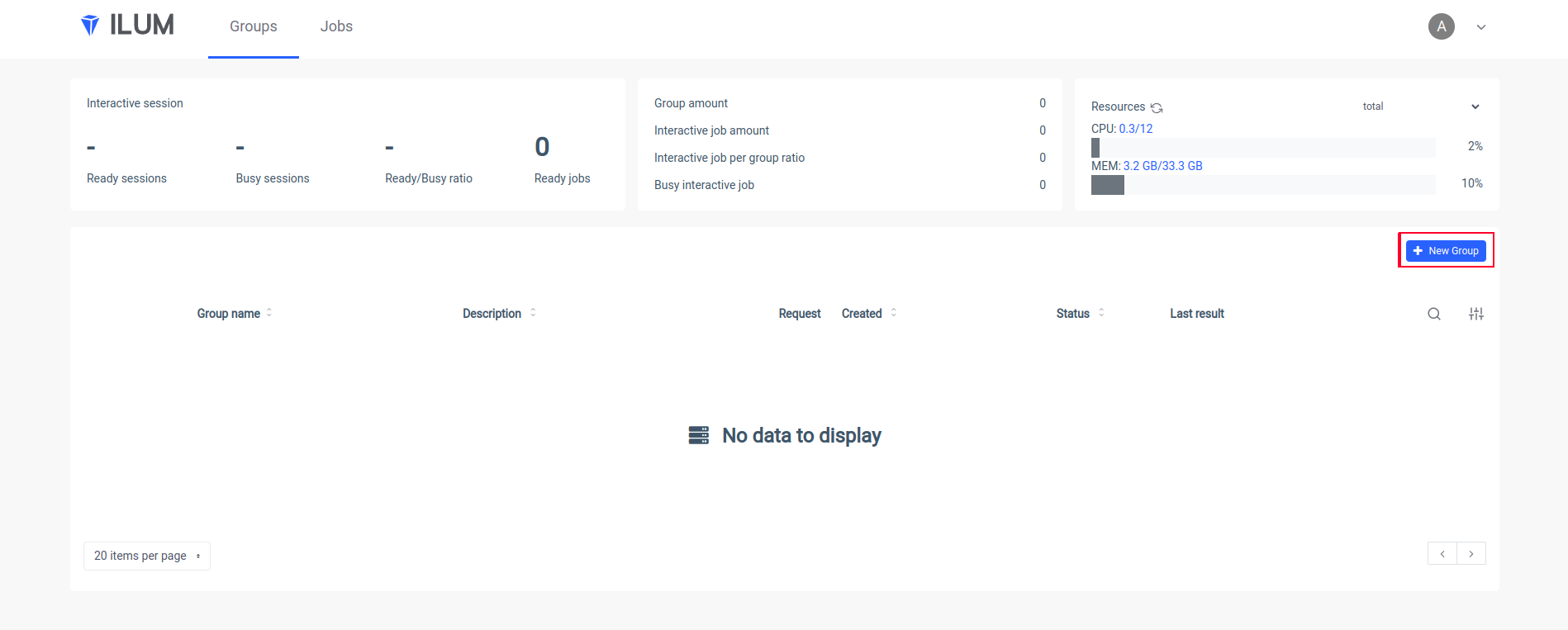
Mettez le nom d’un groupe, choisissez ou créez un cluster, téléchargez votre fichier jar et appliquez les modifications :
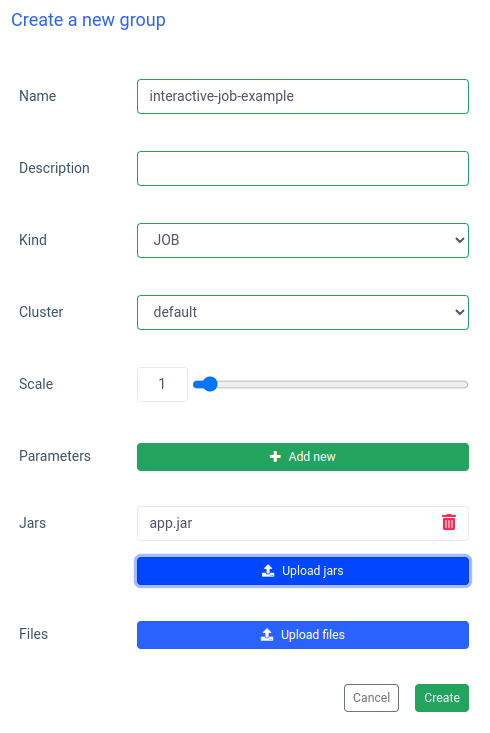
Ilum créera un pod de pilote Spark et vous pourrez contrôler le nombre de pods Spark Executor en les mettant à l’échelle. Une fois que le conteneur Spark est prêt, exécutons les tâches :
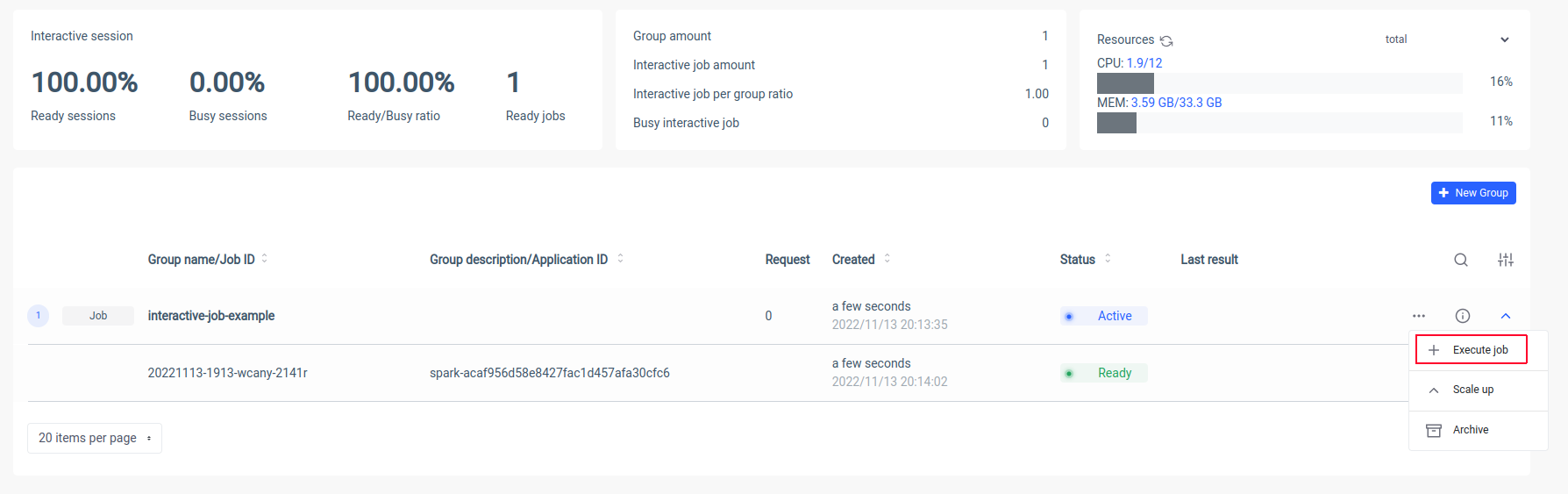
Maintenant, nous devons mettre le nom canonique de notre classe Scala
interactive.job.example.InteractiveJobExample et définissez le paramètre slices au format JSON :
{
« config » : {
« tranches » : « 10 »
}
} Vous devriez voir le résultat juste après le début du travail
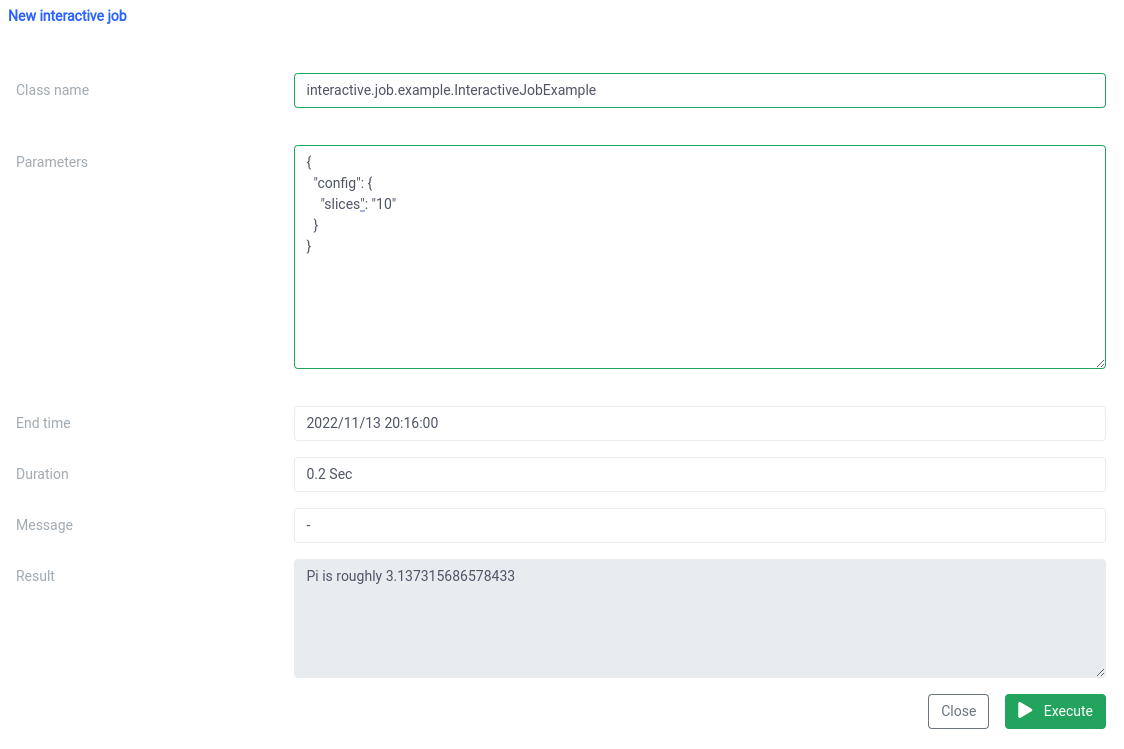
Vous pouvez modifier les paramètres et réexécuter une tâche et vos calculs seront effectués sur-le-champ.
Comparaison interactive et individuelle des offres d’emploi
Dans Ilum, vous pouvez également exécuter une seule tâche. La différence la plus importante par rapport au mode interactif est que vous n’avez pas besoin d’implémenter l’API Job. Nous pouvons utiliser le jar SparkPi à partir d’exemples Spark :
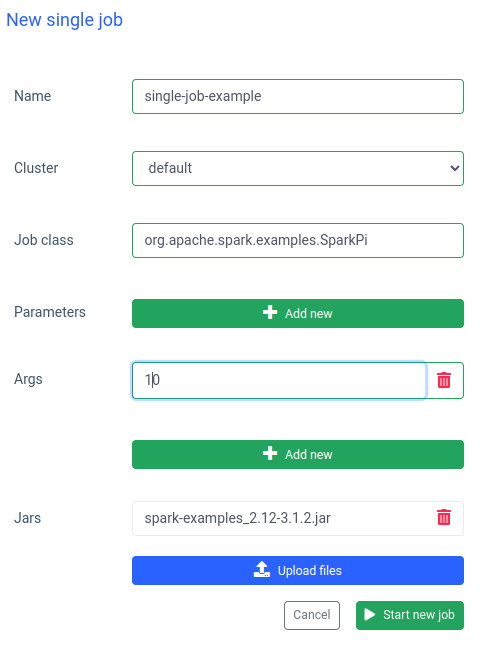
L’exécution d’une tâche comme celle-ci est également rapide, mais les tâches interactives le sont 20 fois plus rapide (4 s vs 200 ms) . Si vous souhaitez démarrer une tâche similaire avec d’autres paramètres, vous devrez préparer une nouvelle tâche et télécharger à nouveau le pot.
Comparaison entre Ilum et Apache Spark
J’ai configuré Apache Spark localement avec un Bitnami/Étincelle image docker. Si vous souhaitez également exécuter Spark sur votre machine, vous pouvez utiliser docker-compose :
$ curl -LO https://raw.githubusercontent.com/bitnami/containers/main/bitnami/spark/docker-compose.yml
$ docker-compose up Une fois que Spark est en cours d’exécution, vous devriez pouvoir accéder à localhost :8080 et voir l’interface utilisateur de l’administrateur. Nous devons obtenir l’URL Spark à partir du navigateur :

Ensuite, nous devons ouvrir le conteneur Spark en mode interactif à l’aide de
$ docker exec -<containerid>it -- bash 
Et maintenant, à l’intérieur du conteneur, nous pouvons soumettre le job sparkPi. Dans ce cas, vous utiliserez SparkiPi à partir de l’exemple jar et, en paramètre maître, mettrez l’URL du navigateur :
$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi\
--master spark://78c84485d233:7077 \
/opt/bitnami/spark/examples/jars/spark-examples_2.12-3.3.0.jar\
10 Résumé
Comme vous pouvez le voir dans l’exemple ci-dessus, vous pouvez éviter la configuration et l’installation compliquées de votre client Spark en utilisant Ilum. Ilum prend le relais et met à votre disposition une interface simple et pratique. De plus, il vous permet de vous affranchir des limitations d’Apache Spark, dont l’initialisation peut prendre beaucoup de temps. Si vous devez effectuer de nombreuses exécutions de tâches avec une logique similaire mais des paramètres différents et que vous souhaitez que les calculs soient effectués immédiatement, vous devez absolument utiliser le mode de tâche interactive.

Similitudes avec Apache Livy
Ilum est un outil cloud natif pour la gestion des déploiements Apache Spark sur Kubernetes. Il est similaire à Apache Livy en termes de fonctionnalités : il peut contrôler une session Spark sur l’API REST et créer une interaction en temps réel avec un cluster Spark. Cependant, Ilum est conçu spécifiquement pour les environnements modernes et natifs du cloud.
Nous avons utilisé Apache Livy dans le passé, mais nous avons atteint le point où Livy n’était tout simplement pas adapté aux environnements modernes. Tite-Live est obsolète par rapport à Ilum. En 2018, nous avons commencé à migrer tous nos environnements vers Kubernetes, et nous avons dû trouver un moyen de déployer, surveiller et maintenir Apache Spark sur Kubernetes. C’était l’occasion idéale pour construire Ilum.