Comment exécuter Apache Spark sur Kubernetes en moins de 5 minutes

Des outils comme Ilum contribueront grandement à simplifier le processus d’installation d’Apache Spark sur Kubernetes. Ce guide vous guidera, étape par étape, sur la façon de bien exécuter Spark sur votre cluster Kubernetes. Avec Ilum, le déploiement, la gestion et la mise à l’échelle des clusters Apache Spark se font facilement et naturellement.
Introduction
Aujourd’hui, nous allons vous montrer comment être opérationnel avec Apache Spark sur K8s. Il existe de nombreuses façons de le faire, mais la plupart sont complexes et nécessitent plusieurs configurations. Nous utiliserons Ilum car cela fera toute la configuration du cluster pour nous. Dans le prochain article de blog, nous comparerons l’utilisation avec l’opérateur Spark.
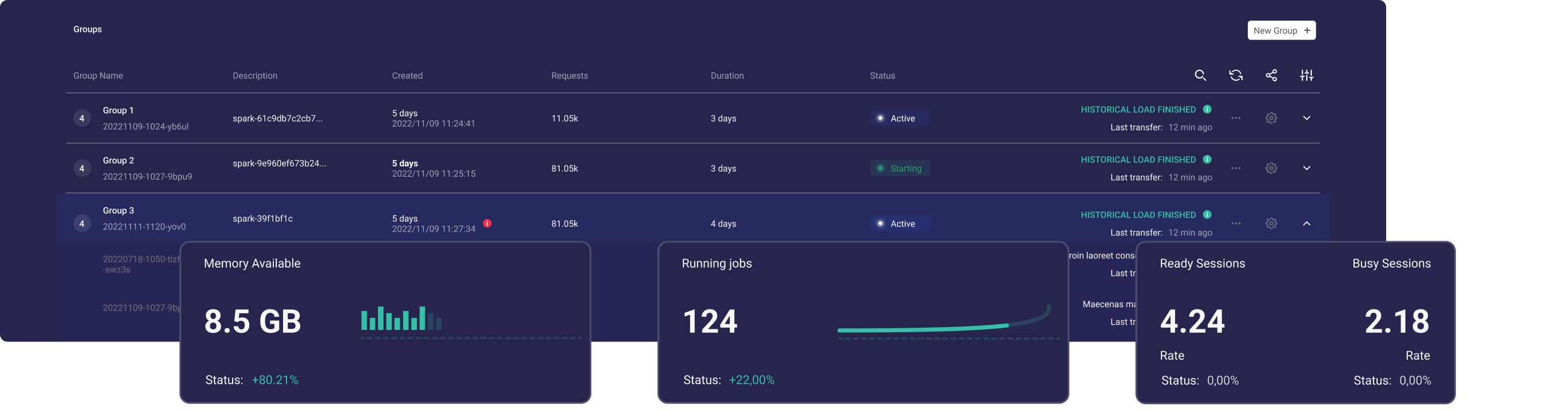
Ilum est un data lakehouse modulaire gratuit qui permet de déployer et de gérer facilement des clusters Apache Spark. Il dispose d’une API simple pour définir et gérer Spark, il gérera toutes les dépendances. Il aide à la création de votre propre étincelle gérée.
Avec Ilum, vous pouvez déployer des clusters Spark en quelques minutes et commencer immédiatement à exécuter des applications Spark. Ilum vous permet d’effectuer facilement un scale-out et dans vos clusters Spark, en gérant plusieurs clusters Spark à partir d’une seule interface utilisateur.
Avec Ilum, la prise en main est facile si vous êtes relativement nouveau sur Apache Spark sur Kubernetes.
Guide étape par étape pour installer Apache Spark sur Kubernetes
Démarrage rapide
Nous supposons que vous avez un cluster Kubernetes en cours d’exécution, mais au cas où ce n’est pas le cas, consultez ces instructions pour configurer un cluster Kubernetes sur le minikube. Vérifiez comment installer minikube .
Configurer un cluster Kubernetes local
- Installez Minikube : Exécutez la commande suivante pour installer Minikube avec les ressources recommandées. Cela installera Minikube avec 6 vCPU et 12288 Mo de mémoire, y compris le module complémentaire de serveur de métriques nécessaire à la surveillance.
minikube start --cpus 6 --memory 12288 --addons metrics-server Une fois que vous avez un cluster Kubernetes en cours d’exécution, il suffit de quelques commandes pour installer Ilum :
Installer Spark sur Kubernetes avec Ilum
- Ajouter Référentiel Ilum Helm
helm repo add ilum https://charts.ilum.cloud - Installer ilum dans votre cluster
Here we have a few options.
a) The recommended one is to start with a few additional modules turned on (Data Lineage, SQL, Data Catalog).
helm install ilum ilum/ilum \
--set ilum-hive-metastore.enabled=true \
--set ilum-core.metastore.enabled=true \
--set ilum-sql.enabled=true \
--set ilum-core.sql.enabled=true \
--set global.lineage.enabled=trueb) you can also start with the most basic option which has only Spark and Jupyter notebooks.
helm install ilum ilum/ilum c) there is also an option to use ilum's module selection tool ici .
minikube ssh docker pull ilum/core:6.6.0
Cette configuration devrait prendre environ deux minutes. Ilum se déploiera dans votre cluster Kubernetes, le préparant à gérer les tâches Spark.
Une fois l’Ilum installé, vous pouvez accéder à l’interface utilisateur avec port-forward et localhost :9777.
- Redirection de port vers l’interface utilisateur d’accès : Utilisez la redirection de port Kubernetes pour accéder à l’interface utilisateur Ilum.
kubectl port-forward svc/ilum-ui 9777:9777 Utiliser admin/admin comme informations d’identification par défaut. Vous pouvez les modifier au cours de la Processus de déploiement .
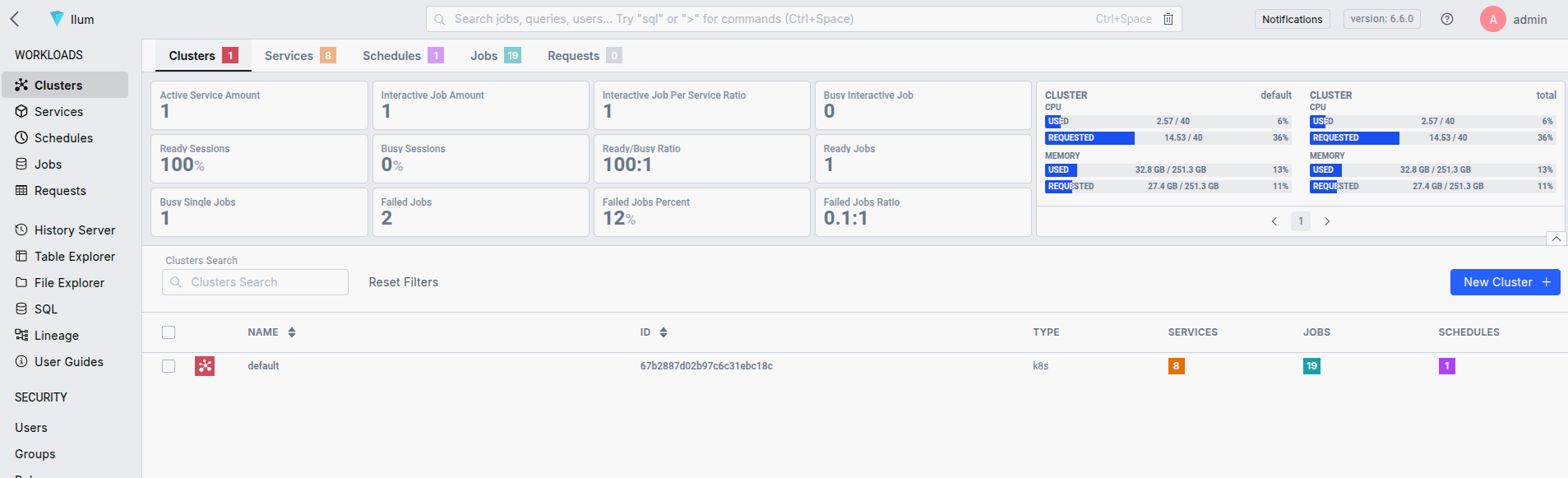
C’est tout, votre cluster kubernetes est maintenant configuré pour gérer les tâches Spark. Ilum fournit une API et une interface utilisateur simples qui facilitent l’envoi d’applications Spark. Vous pouvez également utiliser le bon vieux Spark Soumettre .
Déployer l’application Spark sur Kubernetes
Commençons maintenant un simple travail d’étincelle. Nous utiliserons l’exemple « SparkPi » de la Spark documentation . Vous pouvez utiliser le fichier jar à partir de ce lien .
ilum ajouter spark job
Ilum va créer un pod kubernetes de pilote Spark, il utilise l’image docker Spark version 3.x. Vous pouvez contrôler le nombre de pods d’exécuteur Spark en les mettant à l’échelle sur plusieurs nœuds. C’est la façon la plus simple de soumettre des demandes d’étincelles à K8s.

L’exécution de Spark sur Kubernetes est vraiment facile et sans friction avec Ilum. Il configurera l’ensemble de votre cluster et vous présentera une interface où vous pourrez gérer et surveiller votre cluster Spark. Nous pensons que les applications Spark sur Kubernetes sont l’avenir du Big Data. Avec Kubernetes, les applications Spark seront en mesure de gérer d’énormes volumes de données de manière beaucoup plus fiable, donnant ainsi des informations précises et pouvant prendre des décisions avec le Big Data.
Soumission d’une application Spark à Kubernetes (ancien style)
L’envoi d’une tâche Spark à un cluster Kubernetes implique l’utilisation de la commande étincelle-soumission script avec des configurations spécifiques à Kubernetes. Voici un guide étape par étape :
Escalier :
-
Préparer l’application Spark : Empaquetez votre application Spark dans un fichier JAR (pour Scala/Java) ou un script Python.
-
Utiliser
étincelle-soumissionà déployer : Exécutez leétincelle-soumissionavec des options spécifiques à Kubernetes :./bin/spark-submit \ --master k8s ://https ://<k8s-apiserver-host> :<k8s-apiserver-port> \ --deploy-mode cluster \ --name application-spark_app \ --class org.apache.spark.examples.SparkPi \ --conf spark.executor.instances=3 \ --conf spark.kubernetes.container.image=<your-spark-image> \ local:///path/to/your-app.jarRemplacer:
<k8s-apiserver-host>: votre hôte de serveur d’API Kubernetes.<k8s-apiserver-port>: le port de votre serveur d’API Kubernetes.<your-spark-image>: L’image Docker contenant Spark.local:///path/to/your-app.jar: Chemin d’accès au JAR de votre application dans l’image Docker.
Configurations clés :
--maître: spécifie l’URL de l’API Kubernetes.--deploy-mode:Se mettre àGrappepour exécuter le pilote à l’intérieur du cluster Kubernetes.--nom: nomme votre application Spark.--classe: Classe principale de votre application.--conf spark.executor.instances: Nombre de pods exécuteurs.--conf spark.kubernetes.container.image: Image Docker pour les pods Spark.
Pour plus de détails, consultez la Documentation Apache Spark sur l’exécution sur Kubernetes .
2. Création d’une image Docker personnalisée pour Spark
La création d’une image Docker personnalisée vous permet d’empaqueter votre application Spark et ses dépendances, ce qui garantit la cohérence entre les environnements.
Escalier :
-
Créer un Dockerfile : Définir l’environnement et les dépendances.
# Utiliser l’image de base officielle de Spark DE l’étincelle :3.5.3 # Définir les variables d’environnement ENV SPARK_HOME=/opt/étincelle ENV PATH=$PATH :$SPARK_HOME/bin # Copiez le JAR de votre application dans l’image COPY your-app.jar $SPARK_HOME/exemples/jars/ # Définir le point d’entrée pour exécuter votre application ENTRYPOINT ["spark-submit », « --class », « org.apache.spark.examples.SparkPi », « --master », « local[4] », « /opt/spark/examples/jars/your-app.jar"]Dans ce Dockerfile :
DE l’étincelle :3.5.3: Utilise l’image officielle de Spark comme base.ENV: Définit les variables d’environnement pour Spark.COPIER: Ajoute le JAR de votre application à l’image.POINT D’ENTRÉE: Définit la commande par défaut pour exécuter votre application Spark.
-
Générer l’image Docker : Utilisez Docker pour construire votre image.
docker build -t votre-dépôt/votre-application-spark :latest .Remplacer
votre-dépôt/votre-app-spark-appavec votre référentiel Docker et le nom de votre image. -
Envoyer l’image à un registre : Téléchargez votre image dans un registre Docker accessible par votre cluster Kubernetes.
docker push votre-dépôt/votre-application-spark :latest
Lors de l’utilisation étincelle-soumission est une méthode courante pour déployer des applications Spark, ce n’est peut-être pas l’approche la plus efficace pour les environnements de production. Les soumissions manuelles peuvent entraîner des incohérences et sont difficiles à intégrer dans les flux de travail automatisés. Pour améliorer l’efficacité et la maintenabilité, il est recommandé d’utiliser l’API REST d’Ilum.
Automatisation des déploiements Spark avec l’API REST d’Ilum
Ilum offre une API RESTful robuste qui permet une interaction transparente avec les clusters Spark. Cette API facilite l’automatisation des soumissions, de la surveillance et de la gestion des tâches, ce qui en fait un choix idéal pour les pipelines d’intégration continue/déploiement continu (CI/CD).
Avantages de l’utilisation de l’API REST d’Ilum :
- Automatisation : Intégrez les soumissions de tâches Spark dans les pipelines CI/CD, réduisant ainsi les interventions manuelles et les erreurs potentielles.
- Consistance : Assurer des processus de déploiement uniformes dans différents environnements.
- Évolutivité : Gérez facilement plusieurs clusters et tâches Spark de manière programmatique.
Exemple : Soumission d’une tâche Spark via l’API REST d’Ilum
Pour soumettre une tâche Spark à l’aide de l’API REST d’Ilum, vous pouvez effectuer une requête HTTP POST avec les paramètres nécessaires. Voici un exemple simplifié utilisant friser :
curl -X POST https://<ilum-server>/api/v1/job/submit \
-H « Type-de-contenu : multipart/données-de-formulaire » \
-F « nom=exemple-de-travail » \
-f « clusterName=default » \
-F « jobClass=org.apache.spark.examples.SparkPi » \
-F « jars=@/chemin/vers/your-app.jar » \
-F "jobConfig=spark.executor.instances=3 ; spark.executor.memory=4g" Dans cette commande :
nom: Spécifie le nom de la tâche.clusterName: Indique le cluster cible.jobClass: Définit la classe principale de votre application Spark.Pots: Télécharge le fichier JAR de votre application.jobConfig: Définit les configurations Spark, telles que le nombre d’exécuteurs et l’allocation de mémoire.
Pour plus d’informations sur les points de terminaison et les paramètres de l’API, reportez-vous à la section Documentation de l’API Ilum .
Améliorer l’efficacité grâce aux tâches d’étincelle interactives
Au-delà de l’automatisation des soumissions de tâches, la transformation des tâches Spark en microservices interactifs permet d’optimiser considérablement l’utilisation des ressources et les temps de réponse. Ilum prend en charge la création de sessions Spark interactives de longue durée qui peuvent traiter des données en temps réel sans avoir à initialiser un nouveau contexte Spark pour chaque demande.
Avantages des jobs Spark interactifs :
- Latence réduite : élimine le besoin de démarrer un nouveau contexte Spark pour chaque tâche, ce qui accélère l’exécution.
- Optimisation des ressources : Maintient un contexte Spark persistant, permettant une gestion efficace des ressources.
- Évolutivité : Gère plusieurs requêtes simultanément au sein d’une même session Spark.
Pour implémenter une tâche Spark interactive avec Ilum, vous pouvez définir une application Spark qui écoute les données entrantes et les traite en temps réel. Cette approche est particulièrement avantageuse pour les applications nécessitant un traitement et une réponse immédiats des données.
Pour obtenir un guide complet sur la configuration des tâches Spark interactives et l’optimisation de votre cluster Spark, consultez le billet de blog d’Ilum : Comment optimiser votre cluster Spark avec des tâches Spark interactives .
En intégrant l’API REST d’Ilum et en adoptant des tâches Spark interactives, vous pouvez rationaliser vos flux de travail Spark, améliorer l’automatisation et obtenir un environnement de traitement des données plus efficace et évolutif.
Avantages de l’utilisation d’Ilum pour exécuter Spark sur Kubernetes
Ilum est équipé d’une interface utilisateur intuitive et d’une API résiliente pour mettre à l’échelle et gérer les clusters Spark, en configurant quelques applications Spark à partir d’une seule interface. Voici quelques fonctionnalités intéressantes à cet égard :
- Facilité d’utilisation : Ilum simplifie la configuration et la gestion de Spark sur Kubernetes grâce à une interface utilisateur Spark intuitive, éliminant ainsi les processus de configuration complexes.
- Déploiement rapide : Configurez, déployez et mettez à l’échelle des clusters Spark en quelques minutes pour accélérer l’exécution et le test des applications immédiatement.
- Évolutivité : À l’aide de l’API Kubernetes, mettez facilement à l’échelle les clusters Spark pour répondre à vos besoins de traitement des données, garantissant ainsi une utilisation optimale des ressources.
- Modularité : Ilum est livré avec un cadre modulaire qui permet aux utilisateurs de choisir et de combiner différents composants tels que Spark History Server, Apache Jupyter, Minio, et bien plus encore.
Migration à partir d’Apache Hadoop Yarn
Maintenant qu’Apache Hadoop Yarn est en profonde stagnation, de plus en plus d’organisations envisagent de migrer de Yarn vers Kubernetes. Cela est attribué à plusieurs raisons, mais la plus courante est que Kubernetes fournit une plateforme plus résiliente et plus flexible en matière de gestion des charges de travail Big Data.
Généralement, il est difficile d’effectuer une migration de plateforme de traitement de données d’Apache Hadoop Yarn vers une autre. De nombreux facteurs doivent être pris en compte lorsqu’un tel changement est effectué : la compatibilité des données, la vitesse et le coût du traitement. Cependant, cela se passerait sans heurts et avec succès si la procédure était bien planifiée et exécutée.
Kubernetes est un choix assez naturel lorsqu’il s’agit de charges de travail Big Data en raison de sa capacité inhérente à pouvoir évoluer horizontalement. Mais, avec Hadoop Yarn, vous êtes limité au nombre de nœuds dans votre cluster. Vous pouvez augmenter et réduire le nombre de nœuds à l’intérieur d’un cluster Kubernetes à la demande.
Il permet également des fonctionnalités qui ne sont pas disponibles dans Yarn, par exemple : l’auto-réparation et la mise à l’échelle horizontale.
Il est temps de passer à Kubernetes ?
Le monde du Big Data continue d’évoluer, tout comme les outils et les technologies utilisés pour les gérer. Pendant des années, Apache Hadoop YARN a été la norme de facto pour la gestion des ressources dans les environnements Big Data. Mais avec l’essor des technologies de conteneurisation et d’orchestration comme Kubernetes, est-il temps de faire le saut ?
Kubernetes a gagné en popularité en tant que plateforme d’orchestration de conteneurs, et pour de bonnes raisons. Il est flexible, évolutif et relativement facile à utiliser. Si vous utilisez toujours une infrastructure traditionnelle basée sur des machines virtuelles, il est peut-être temps de passer à Kubernetes.
Si vous travaillez avec des conteneurs, vous devez absolument vous intéresser à Kubernetes. Il peut vous aider à gérer et à déployer vos conteneurs plus efficacement, et il est particulièrement utile si vous travaillez avec un grand nombre de conteneurs ou si vous déployez vos conteneurs sur une plate-forme cloud.
Kubernetes est également un excellent choix si vous recherchez un outil d’orchestration soutenu par une grande entreprise technologique. Google utilise Kubernetes depuis des années pour gérer ses propres applications conteneurisées, et ils ont investi beaucoup de temps et de ressources pour en faire un excellent outil.
Il n’y a pas de gagnant clair dans le débat YARN vs Kubernetes. La meilleure solution pour votre organisation dépendra de vos besoins spécifiques et de vos cas d’utilisation. Si vous êtes à la recherche d’une solution de gestion des ressources plus flexible et évolutive, Kubernetes vaut la peine d’être considéré. Si vous avez besoin d’une meilleure prise en charge des applications héritées, YARN peut être une meilleure option.
Quelle que soit la plateforme que vous choisissez, Ilum peut vous aider à en tirer le meilleur parti. Notre plateforme est conçue pour fonctionner à la fois avec YARN et Kubernetes, et notre équipe d’experts peut vous aider à choisir et à mettre en œuvre la bonne solution pour votre organisation.
Cluster Spark managé
Un cluster Spark géré est une solution basée sur le cloud qui facilite le provisionnement et la gestion des clusters Spark. Il fournit une interface Web pour la création et la gestion de clusters Spark, ainsi qu’un ensemble d’API pour l’automatisation des tâches de gestion de cluster. Les clusters Spark managés sont souvent utilisés par les scientifiques des données et les développeurs qui souhaitent provisionner et gérer rapidement des clusters Spark sans avoir à se soucier de l’infrastructure sous-jacente.
Ilum offre la possibilité de créer et de gérer votre propre cluster Spark, qui peut être exécuté dans n’importe quel environnement, y compris dans le cloud, sur site ou une combinaison des deux.

Les avantages d’Apache Spark sur Kubernetes
Il y a eu un débat sur la question de savoir si Apache Spark devrait fonctionner sur Kubernetes.
Certaines personnes affirment que Kubernetes est trop complexe et que Spark devrait continuer à fonctionner sur son propre gestionnaire de cluster dédié ou rester dans le cloud. D’autres soutiennent que Kubernetes est l’avenir du traitement du Big Data et que Spark devrait l’adopter.
Nous sommes dans le dernier camp. Nous pensons que Kubernetes est l’avenir du traitement du Big Data et qu’Apache Spark doit fonctionner sur Kubernetes.
Le plus grand avantage de l’utilisation de Spark sur Kubernetes est qu’il permet une mise à l’échelle beaucoup plus facile des applications Spark. En effet, Kubernetes est conçu pour gérer les déploiements d’un grand nombre de conteneurs simultanés. Par conséquent, si vous avez une application Spark qui doit traiter un grand nombre de données, vous pouvez simplement déployer davantage de conteneurs sur le cluster Kubernetes pour traiter les données en parallèle. C’est beaucoup plus facile que de configurer un nouveau cluster Spark sur EMR chaque fois que vous devez augmenter votre traitement. Vous pouvez l’exécuter sur n’importe quelle plateforme cloud (AWS, Google Cloud, Azure, etc.) ou sur site. Cela signifie que vous pouvez facilement déplacer vos applications Spark d’un environnement à un autre sans avoir à vous soucier de changer de gestionnaire de cluster.
Un autre avantage énorme est qu’il permet des flux de travail plus flexibles. Par exemple, si vous devez traiter des données provenant de plusieurs sources, vous pouvez facilement déployer différents conteneurs pour chaque source et les faire traiter en parallèle. C’est beaucoup plus facile que d’essayer de gérer un flux de travail complexe sur un seul cluster Spark.
Kubernetes dispose de plusieurs fonctionnalités de sécurité qui en font une option plus attrayante pour l’exécution d’applications Spark. Par exemple, Kubernetes prend en charge le contrôle d’accès basé sur les rôles, qui vous permet d’affiner l’accès à votre cluster Spark.
Alors voilà. Ce ne sont là que quelques-unes des raisons pour lesquelles nous pensons qu’Apache Spark devrait fonctionner sur Kubernetes. Si vous n’êtes pas convaincu, nous vous encourageons à l’essayer par vous-même. Nous pensons que vous serez surpris de voir à quel point cela fonctionne bien.
Ressources additionnelles
- Vérifiez comment installer Minikube
- Kubernetes Documentation
- Site officiel d’Ilum
- Documentation officielle d’Ilum
- Ilum Helm Chart
Conclusion
Ilum simplifie le processus d’installation et de gestion d’Apache Spark sur Kubernetes, ce qui en fait un choix idéal pour les débutants et les utilisateurs expérimentés. En suivant ce guide, vous disposerez d’un cluster Spark fonctionnel fonctionnant sur Kubernetes en un rien de temps.