Clusters et stockages
Aperçu
Gestion des clusters
La gestion de l’infrastructure Spark au sein d’un seul cluster présente de nombreux défis. Notre objectif est de nous assurer que l’infrastructure dispose de toutes les fonctionnalités essentielles, telles que la visualisation des données et le suivi des flux de données. Nous voulons également qu’il soit sécurisé, avec des capacités de réplication et de gestion des versions intégrées. De plus, il est crucial de surveiller la santé et le rendement de notre travail. Cependant, l’intégration de toutes ces fonctionnalités nécessite une configuration chronophage, ce qui ajoute de la complexité et des coûts.
De plus, lors de la transition vers une infrastructure multi-clusters, ces tâches doivent souvent être répliquées pour chaque cluster supplémentaire, ce qui entraîne des coûts potentiellement élevés. De plus, les dépenses de maintenance nécessitent une augmentation linéaire à chaque cluster supplémentaire.
Ilum n’offre pas seulement Intégration automatique de toutes les fonctionnalités mentionnées ci-dessus dans votre infrastructure de données, mais il permet également Transition vers un multicluster Architecture aussi transparente que possible. Tout ce que vous devez gérer, c’est la mise en réseau et l’accès
Avec Ilum, vous pouvez gérer votre architecture multi-clusters via un plan de contrôle central. Tout peut être fait dans l’application Ilum.
Gestion des stockages
Dans certains cas, l’utilisation de plusieurs solutions de stockage dans votre infrastructure de données devient nécessaire. Cela peut être dû à des considérations de coût, à des fonctionnalités uniques offertes par différents fournisseurs ou à la nécessité d’avoir un stockage dans plusieurs régions pour réduire la latence du réseau. Cependant, l’intégration de plusieurs stockages dans une architecture Spark implique souvent des tâches répétitives et chronophages, telles que la configuration de chaque tâche Spark individuellement pour accéder au stockage.
Ilum simplifie ce processus pour vous. Tout ce que vous avez à faire est de configurer le stockage une seule fois en ajoutant les détails d’authentification lors de son attachement au cluster. Après cela, toutes les tâches Ilum sont automatiquement autorisées à lire et à écrire dans le stockage, éliminant ainsi le besoin de configuration manuelle pour chaque tâche.
Par exemple, lors de l’utilisation du stockage MinIO intégré, chaque Jobs Ilum sera Préconfiguré avec ces paramètres d’étincelle :

Des paramètres similaires seront ajoutés pour chaque stockage dans le cluster.
Dans Ilum, vous pouvez utiliser 4 types de stockages : GCS, S3, WASBS, HDFS.
HDFS Storage Configuration
When connecting an HDFS cluster as a storage backend, ilum automatically configures Spark jobs with the necessary Hadoop properties. For manual or advanced HDFS configuration, the following Spark properties are commonly required:
# Core HDFS connection
spark.hadoop.fs.defaultFS=hdfs://:8020
# HA NameNode configuration (if applicable)
spark.hadoop.dfs.nameservices=mycluster
spark.hadoop.dfs.ha.namenodes.mycluster=nn1,nn2
spark.hadoop.dfs.namenode.rpc-address.mycluster.nn1=namenode1:8020
spark.hadoop.dfs.namenode.rpc-address.mycluster.nn2=namenode2:8020
spark.hadoop.dfs.client.failover.proxy.provider.mycluster=org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
For Kubernetes-based deployments, mount the Hadoop core-site.xml et hdfs-site.xml configuration files into Spark pods:
spark.kubernetes.driver.volumes.configMap.hadoop-config.mount.path: /etc/hadoop/conf
spark.kubernetes.driver.volumes.configMap.hadoop-config.mount.readOnly: vrai
spark.kubernetes.executor.volumes.configMap.hadoop-config.mount.path: /etc/hadoop/conf
spark.kubernetes.executor.volumes.configMap.hadoop-config.mount.readOnly: vrai
spark.driver.extraJavaOptions: -Dhadoop.home.dir=/etc/hadoop/conf
spark.executor.extraJavaOptions: -Dhadoop.home.dir=/etc/hadoop/conf
Ensure that HDFS ports (default: 8020 for RPC, 9870 for WebUI) are accessible from the Kubernetes cluster where ilum runs. For cross-network deployments, configure appropriate network policies or VPN tunnels.
Pour en savoir plus sur l’ajout de stockages à des clusters, rendez-vous sur Guide d’ajout de stockages.
Gestion centralisée des travaux
Problème
Prenons un exemple. Nous avons 10 clusters sur différentes régions et nous souhaitons déployer un job sur l’une d’entre elles. À quoi cela ressemblerait-il sans Ilum ?
Nous aurions besoin de mettre à jour kubectl config pour définir le contexte de cluster choisi comme actuel.
kubectl config use-context cluster_i_context
Cela signifie que nous aurions besoin de contenir un énorme fichier kubeconfig avec chaque cluster écrit là en tant que contexte :
apiVersion: v1
Clusters:
- Grappe:
autorité-de-certification: /chemin/vers/ca-1.CRT
serveur: https://<cluster-1-Ip>:6443
nom: Grappe-1
...
- Grappe:
autorité-de-certification: /chemin/vers/ca-n.crt
serveur: https://<cluster-n-Ip>:6443
nom: Grappe-n
Contextes:
- contexte:
Grappe: Grappe-1
Namespace: faire défaut
utilisateur: utilisateur-1
nom: Grappe-1-contexte
...
- contexte:
Grappe: Grappe-n
Namespace: faire défaut
utilisateur: utilisateur-n
nom: Grappe-n-contexte
contexte-actuel: Grappe-Je
gentil: Configurer
préférences: {}
Utilisateurs:
- nom: utilisateur-1
utilisateur:
certificat-client: /chemin/vers/client/certificat-1.CRT
clé-client: /chemin/vers/client/clé-1.key
...
- nom: utilisateur-n
utilisateur:
certificat-client: /chemin/vers/client/certificat-n.crt
clé-client: /chemin/vers/client/clé-n.key
Une telle approche présente plusieurs défis. Considérez les scénarios suivants :
-
Kubeconfig perdu: Que se passe-t-il si vous perdez votre fichier kubeconfig ? Cela perturberait votre accès au cluster, nécessitant une récupération ou une régénération manuelle.
-
Dépendance du certificat: Que se passe-t-il si le kubeconfig s’appuie sur un certificat stocké localement sur votre PC, et que vous le perdez ? Le rétablissement de l’accès deviendrait lourd.
-
Accès multi-utilisateurs: Si vous souhaitez accorder l’accès au cluster à plusieurs personnes, auriez-vous besoin de distribuer le fichier kubeconfig et les certificats à tout le monde ? Ce processus est non seulement inefficace, mais présente également des risques pour la sécurité.
-
Mises à jour des certificats: Que se passe-t-il lorsque les certificats expirent ou doivent être mis à jour ? Vous devrez mettre à jour le fichier kubeconfig et les certificats de chaque utilisateur, ce qui ajouterait encore plus de complexité.
Même si vous résolvez tous ces problèmes, vous devez toujours créer un travail Spark. Par exemple, vous pouvez soumettre une tâche à l’aide de la commande suivante :
étincelle-soumission \
--maître k8s://https://<kubernetes-api-server>:6443 \
--deploy-mode cluster \
--nom spark-app \
--classe com.example.MyApp \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=<spark-image> \
/chemin/vers/application.jar
Et vous devrez exécuter cette commande chaque fois que vous redimensionnez le travail ou mettez à jour les configurations, ce qui entraîne beaucoup d’efforts inutiles et d’inefficacité.
Solution
Ilum élimine tous ces problèmes grâce à son approche rationalisée :
- Configuration unique: Il suffit d’ajouter une fois les certificats du cluster pour connecter Ilum à votre cluster, et le tour est joué. Pas besoin de gérer de longs fichiers kubeconfig ou de suivre plusieurs certificats et clés.
- Pas de configuration côté ingénieur: Vos ingénieurs n’auront pas à configurer manuellement les connexions de cluster ou à gérer les fichiers kubeconfig.
- Gestion pilotée par l’interface utilisateur: Oubliez l’utilisation de kubectl pour déployer des tâches Spark. Avec Ilum, tout est géré via une interface utilisateur intuitive.
Pour commencer, il suffit d’ajouter un cluster en suivant le guide approprié/l
Si vous avez besoin de mettre à jour des certificats ou d’autres configurations de cluster, cliquez simplement sur l’icône Éditer pour le cluster souhaité et suivez les mêmes guides.
Remarque : Les tâches lancées avec Ilum nécessitent un accès au plan de contrôle centralisé. Pour ce faire, vous devez exposer les services Ilum au monde extérieur et créer des services externes dans votre cluster distant.
Une fois votre cluster connecté, accédez à la liste des clusters et sélectionnez le cluster sur lequel vous souhaitez déployer votre tâche Spark. À partir de là, vous pouvez déployer Ilum Jobs en suivant ces guides :
- Comment exécuter un Job Spark simple
- Comment exécuter un Job Spark interactif
- Comment exécuter un groupe de codes interactif
Avec les Emplois interactifs , vous pouvez configurer les paramètres Spark, charger des fichiers, déployer un pod Spark une fois et exécuter vos applications Spark plusieurs fois sans redéployer. De plus, le Groupes de codes interactifs vous permet d’exécuter du code Spark directement dans l’interface utilisateur d’Ilum.
À tout moment, vous pouvez :
- Éditer les paramètres Spark de votre travail ou les ressources affectées.
- Redimensionner le travail au besoin.
- Redémarrer ou supprimer tâches directement depuis l’interface utilisateur sans jamais utiliser la console.
Ilum simplifie la gestion des clusters et des tâches Spark, ce qui permet de gagner du temps et de réduire la complexité opérationnelle.
Surveillance centralisée
Dans Ilum, vous pouvez surveiller toutes les informations vitales sur votre infrastructure de données à partir de Plan de contrôle central
Serveur d’historique
Lorsque Spark exécute votre application, il crée un plan d’exécution, en le décomposant en étapes, travaux et tâches distincts. En cours de route, il suit des indicateurs clés tels que le nombre de lignes et d’octets de données transférés entre les étapes, ainsi que d’autres détails de performance essentiels.
Dans Ilum, toutes les tâches envoient ces informations à l' Journal des événements, qui est ensuite organisé par le serveur d’historique. Cela vous permet d’analyser facilement les données directement dans l’interface utilisateur d’Ilum.


Le journal des événements est stocké sur le stockage Ilum par défaut. Pour collecter des données à partir de tâches Spark exécutées sur des clusters distants, vous devez exposer le stockage. Des instructions détaillées pour ce processus se trouvent sur le Guide d’ajout GKE
Pour plus d’informations sur le serveur d’historique et sur la surveillance de vos travaux, consultez la page Page de surveillance
Graphite
Graphite est un outil de collecte de métriques similaire à Prometheus, mais fonctionne sur un modèle basé sur le push, ce qui le rend particulièrement bien adapté à une utilisation dans un environnement multi-clusters.
Tous les travaux Ilum sont préconfigurés pour transmettre leurs données de métriques à Graphite, ce qui permet une surveillance centralisée de vos applications et de votre infrastructure.
Pour activer Graphite, suivez les instructions fournies dans la section Page Surveillance . Une fois activé, configurez vos clusters pour qu’ils s’intègrent à Graphite en vous référant à la fonction Page d’ajout GKS.
Traçabilité des données
Lineage est une fonctionnalité d’Ilum qui vous permet de visualiser les relations entre les ensembles de données et les tâches au sein de vos projets.
Par exemple, vous pouvez afficher une visualisation de flux de données montrant comment deux tâches ingèrent des données dans le stockage, après quoi une autre tâche traite ces données dans le jeu de données final. Cela permet de comprendre clairement et intuitivement comment vos données se déplacent et se transforment dans le pipeline.

De telles visualisations sont créées automatiquement par Ilum grâce à la base de données de métadonnées : chaque Job Ilum est préconfiguré pour envoyer des métadonnées sur les tâches à la base de données. L’interface utilisateur d’Ilum utilise ces données pour présenter les relations entre les tâches et les ensembles de données.
En exposant cette base de métadonnées aux clusters distants, vous pouvez facilement observer le flux de données dans une architecture multi-clusters. Pour en savoir plus sur la façon de l’exposer, visitez Page d’ajout GKS
Pour en savoir plus sur le Data Lineage, rendez-vous sur Traçabilité des données page.
Explorateur de fichiers
L’Explorateur de fichiers est une fonctionnalité d’Ilum qui vous permet d’afficher les métadonnées des objets stockés dans tous les systèmes de stockage de tous vos clusters. Il simplifie considérablement la surveillance du stockage en éliminant le besoin de basculer entre différentes configurations IAM, comptes de service ou outils pour accéder au contenu de vos stockages. De plus, il n’est plus nécessaire de partager l’accès au stockage avec les membres de votre équipe, car tout le monde peut facilement afficher le contenu du stockage directement via l’interface utilisateur Ilum.

Pour en savoir plus, visitez Explorateur de fichiers page
Liens
Analyse centralisée des données
Ilum vous permet d’intégrer tous les outils pour rendre possible l’analyse de données grâce à Ilum UI
Metastore
A metastore is a tool that allows you to save information about your data, such as its schema, location, and other metadata on a central, persistent server. To learn more about it, visit the Data catalogs documentation page.
However, you need to expose Hive Metastore Server to remote clusters. You can do this following instructions from Guide d’ajout GKE.
Explorateur de tables
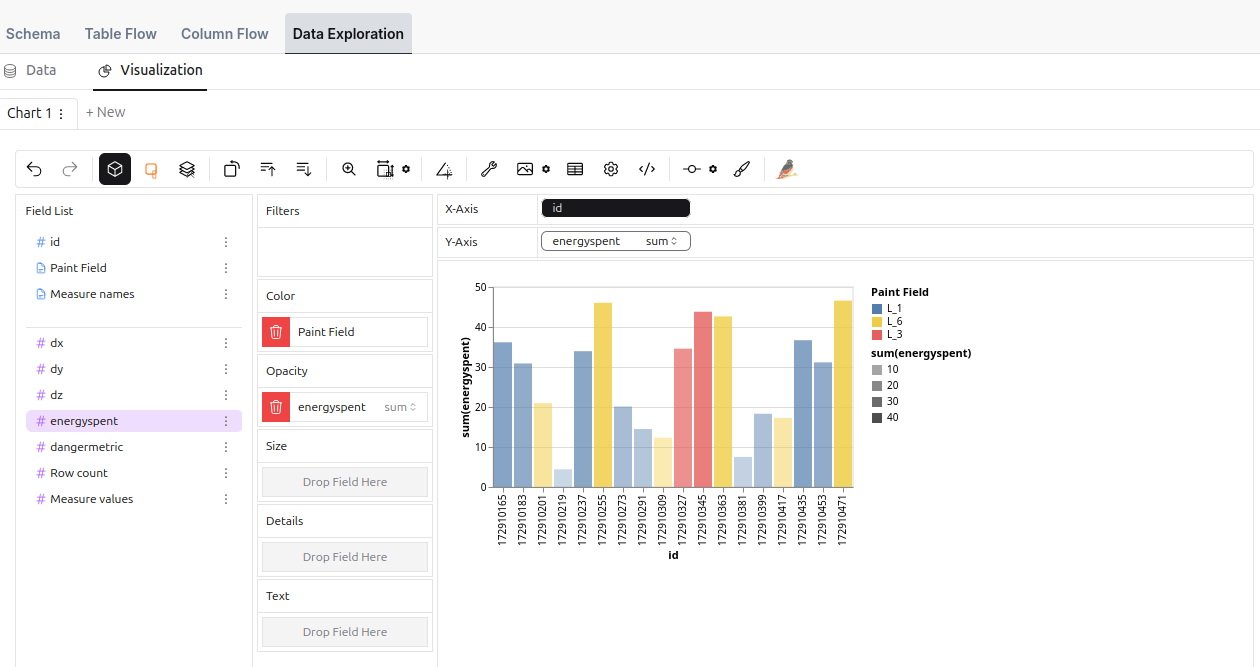
The Table Explorer lets you explore the contents of your metastores and view samples of your data with the Outil d’exploration des données.
To learn more about it, visit the Explorateur de tables page.
Ilum SQL
Similar to the Data Exploration Tool, you can access small portions of data by applying SQL operations. However, Ilum SQL provides greater flexibility by enabling you to run complex SQL queries on tables from the Hive Metastore, allowing for more advanced data exploration and analysis.
To learn more about it, visit Page SQL Ilum